
有個數字先丟出來:在二元分類裡,模型常常最後就是在做一件事——把「0.49」跟「0.51」硬切開,然後你整個系統就跟著那條線走。Logistic Regression 的核心就是用 sigmoid 把線性分數 z 變成機率 p,再用 Maximum Likelihood(最大概似)去找 b0、b1…bn,讓資料在 Bernoulli 假設下的 log-likelihood 最大。
- 你算的不是 y:你先算 log-odds(log(p/(1-p))),再回推 p
- 那條線叫 decision boundary:常見用 p=0.5,但你想設 0.7 也行
- 參數怎麼來:最大概似 → log-likelihood → gradient → 迭代解
- 兩條路:Gradient Descent 或 Newton-Raphson(Hessian 那個)
- 工具會藏細節:sklearn 幫你做,但你得知道它在做什麼
Logistic Regression 到底在算什麼
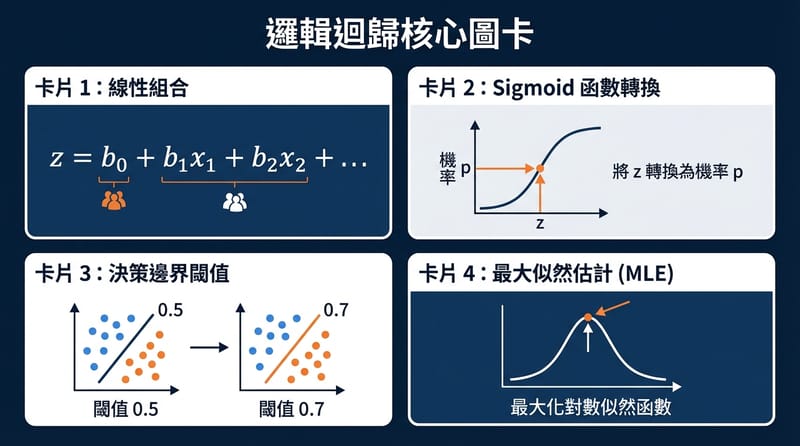
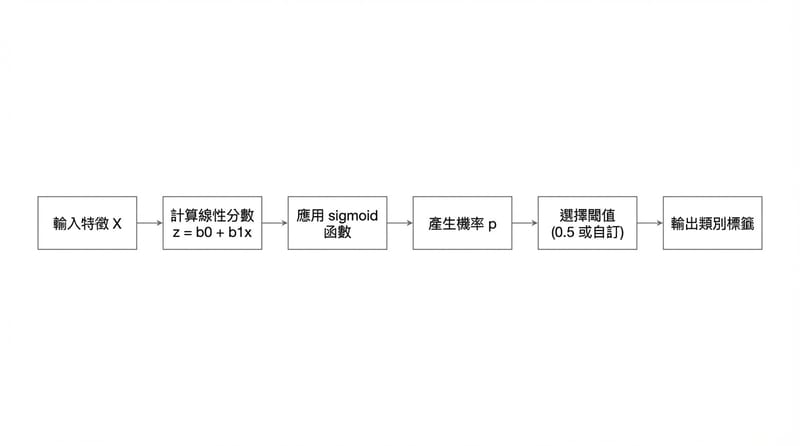
Logistic Regression 是監督式學習的分類模型,輸入特徵 X,輸出機率 p,再用閾值把 p 變成類別。Logistic Regression 的線性部分是 z=b0+b1x1+…+bnxn,而 p=1/(1+exp(-z)) 這個 sigmoid 讓結果落在 0 到 1。
先釐清兩個詞:監督式、分類。監督式就是你手上同時有 X 跟 y,y 是答案卷;分類就是 y 不是連續數字,是一個個標籤,像「會壞 / 不會壞」、「通過 / 沒通過」。
講到「分類」,我腦袋會自動跳到那種工廠機台預測維修的例子:溫度、磨損、濕度、震動…你其實不是想要一個漂亮的連續值,你只想要一句話——兩年內會不會掛。
就這樣。真的。
那為什麼名字裡有 regression:因為它也在做「線性組合」。只是它不直接回傳 y,而是回傳 log-odds。你可以把 log-odds 想成偵探筆記上的「偏向有罪的程度」,分數越大越偏向 1,越小越偏向 0。
log-odds 這句要記:log(p/(1-p)) = z。這句一旦成立,你解出 p,就會長得很眼熟:p = 1/(1+exp(-z))。
sigmoid 的形狀你大概看過:中間斜斜的,上下兩端貼著 0 和 1。它連續、可微分,所以你後面要做導數、做梯度更新,才有路走。
Decision boundary 不是天條 0.5 只是習慣
Decision boundary 是把機率 p 轉成類別的門檻,常見用 p=0.5,但 logistic regression 的閾值可以依需求改成 0.7 或 0.3。門檻改了,precision/recall 的取捨就跟著改,這在不平衡資料或風險成本不同時特別常見。
原文那個學生例子很乾脆:只用「讀書時數 x」一個特徵,z=b0+b1x。假設算出 b0=-4、b1=1,所以 z=-4+x。
然後丟進 sigmoid,你就會得到:
- x=1:z=-3 → p 大概偏小 → 你會猜「fail」
- x=4:z=0 → p=0.5 → 就站在門口,很尷尬
- x=6:z=2 → p 明顯偏大 → 你會猜「pass」
你看,這裡其實已經有一條「線」了:z=0 的位置就是 p=0.5 的位置。線性分數跨過 0,你的判斷就翻面。
多分類也能玩:原文用三段式的門檻很直觀:p≤0.3 失敗、0.3≤p≤0.7 二等、p≥0.7 一等。這其實是在用同一個連續分數去切三塊。
我知道你可能會想吐槽:那 p 到底還是不是「通過機率」?嗯,在這個三段式例子裡,p 更像「表現分數」。名字叫 p,但你心裡要知道它被拿來當尺了。
最大概似 MLE 其實在問 這組參數像不像真兇
Maximum Likelihood Estimate 在 logistic regression 裡是用 Bernoulli 分佈假設 y∈{0,1},把所有樣本的機率乘起來得到 likelihood,再取 log 變成 log-likelihood。訓練的目標是選一組參數 b,使 log-likelihood 最大,等價於讓負的 log-likelihood 最小。
likelihood 跟 probability 差在哪:這個很像偵探在問問題的方向不一樣。
- Probability:給我 X 和模型,算 y 會長什麼樣
- Likelihood:給我 (X, y) 這些已發生的事,哪組參數最說得通
好,進洞。
二元 y 的自然假設:Bernoulli。因為 y 只有 0 或 1。對每個觀測 i,模型給一個 p_i,然後 y_i=1 的機率是 p_i,y_i=0 的機率是 1-p_i。
單一樣本的 pmf:p(y_i|x_i) = p_i^{y_i} (1-p_i)^{1-y_i}。這個式子很「機械」,但超好用:y_i 是 1 就只剩 p_i,y_i 是 0 就只剩 1-p_i。
整包資料的 likelihood:假設各樣本獨立,L = ∏ p_i^{y_i} (1-p_i)^{1-y_i}。
乘積會爆炸難算,所以取 log:
log-likelihood:log L = Σ [ y_i log(p_i) + (1-y_i) log(1-p_i) ]。
然後你把 p_i 換成 sigmoid(z_i),z_i = b0 + b1x_i(多特徵就加到 bn)。整理之後,就得到那個經典目標函數。
我第一次看到這裡的感覺是:欸,原來訓練就是在「把猜對的機率拉高、猜錯的機率壓低」,只是寫成一堆 log。
梯度與 Hessian 兩條路 一條慢慢走 一條扛著二階資訊衝
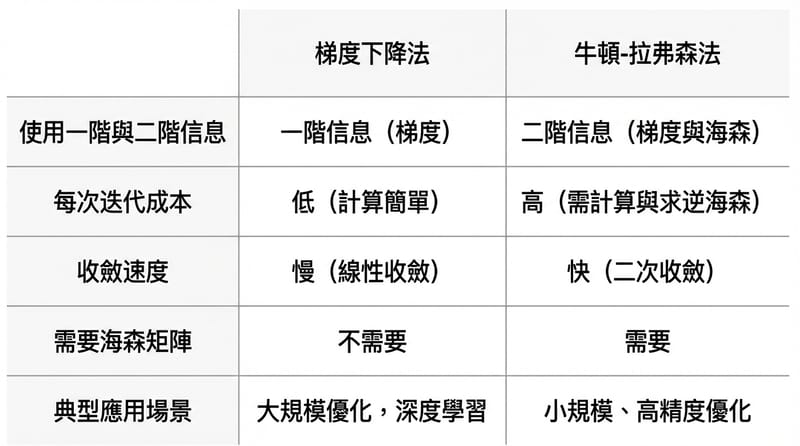
Logistic regression 的參數通常不做 closed-form 解,因為特徵數變多就會變成要解 n 個聯立方程。實務上常用 Gradient Descent 用一階梯度迭代更新,或用 Newton-Raphson 利用 Hessian 做二階更新(等價於解一個線性系統),但計算 Hessian 或其逆在高維時成本很兇。
先講梯度:你對 b0、b1… 做偏微分,會得到一組 gradients。它們在講「參數往哪個方向動,log-likelihood 會變大」。
原文也有提到矩陣寫法:如果把 log-likelihood 記成 l,把 sigmoid 機率記成 p,那個 gradient 會變成一個向量。
你不一定要背矩陣式,但要有畫面:每次更新,就是把參數往「更像真相」的方向推一下。
Gradient Descent 的更新規則:w_new = w_old + α * gradient(如果你在最大化);或 w_new = w_old - α * gradient(如果你在最小化負的 log-likelihood)。
α 是 learning rate。原文給的範圍很大:10^-7 到 10^-1。你可以把它想成「每次走幾步」,步子大會衝過頭,步子小會走到天荒地老。
講到 learning rate 我就想到一件事:你明明只是想把作業跑完,結果卡在「怎麼不收斂」,那種晚上兩點盯著 loss 不動的感覺。很現實。
Newton-Raphson 呢:它用二階資訊,也就是 Hessian H(對 log-likelihood 的二次偏導組成的矩陣)。更新規則長得像:w_new = w_old - H^{-1} * gradient(符號視你在最大化還是最小化)。
但 H^{-1} 這個「反矩陣」本身就很貴,所以實務上常做的是把它改寫成解線性系統,然後用 LU、QR 或 Cholesky 分解去解。
我聽一個做數值線代的朋友說過一句很硬但很真:你不是真的在算反矩陣,你是在解方程。對,這句話會救你很多次。
題外話但很關鍵:很多 log-likelihood 會是 concave(向下彎),所以通常有 global maximum。原文也提了 double derivative 的檢查。意思是:你比較不怕走到「假的山頂」。比較不怕,不代表完全不會出事啦。
如果你是不同族群 你該怎麼用這套想法做決策
Logistic regression 的實務決策通常落在三個旋鈕:特徵工程、閾值設定、以及選擇 solver。不同情境的風險成本不同,最該先動的旋鈕也不同;例如醫療篩檢常先調高 recall 而非死守 0.5 閾值,風控或詐欺偵測也常用自訂閾值配合成本矩陣。
規則:下面是「If This Then That」的用法,偏生活化,但你真的拿去專案裡會用得到。
- 如果你是夜班工程師、只想模型先跑起來:先用 sklearn 的 LogisticRegression 跑 baseline,別一開始就糾結 Newton-Raphson。你先看 confusion matrix 長什麼樣,再回頭調 threshold。先活下來。
- 如果你是資料不平衡的苦主:別死守 p=0.5。你先問「漏抓一個 1 的代價」跟「誤抓一個 1 的代價」哪個更痛,再去選 threshold(像 0.7 或 0.3)。這比你多調十個 feature 還快見效。
- 如果你是產品或營運、在意的是可解釋:log-odds 這件事要拿出來講。係數 b 的正負號就是方向,大小(搭配特徵尺度)大概就是影響程度。你要的是「為什麼被判成 1」,不是「模型說了算」。
- 如果你是銀髮族…欸不是,你是做銀髮族服務的:把閾值想成「提醒要不要打電話關心」而不是「判決」。門檻低一點會多打幾通,門檻高一點可能漏掉真的需要的人。你在設計的是流程,不是考卷。
- 如果你是親子族群的 App 團隊:你要小心 false positive。因為你亂推一次「可能有風險」的通知,家長會直接炸掉。那你就傾向把 threshold 拉高,或至少做分級提示。
你看,logistic regression 不是只有「會不會」;它其實在逼你講清楚:你怕的是哪一種錯。
「Logistic Regression 最像偵探的地方,是它不急著宣判;它先把證據換算成機率,然後逼你自己決定要在哪裡畫線。」
一些小心機與免責聲明 免得你踩雷
Logistic regression 在資料可分、特徵尺度差異大、或類別極不平衡時,常需要正則化與特徵縮放來避免係數暴衝。本文是教育用途的概念整理,不構成醫療、法律或投資建議;若用於高風險決策,請搭配領域專家與合規流程。
小心機一:特徵尺度。你如果一個特徵是「年齡 0-100」,另一個是「收入 0-10,000,000」,係數看起來會很怪,梯度更新也會走得很彆扭。這時候你通常會想做 scaling。
小心機二:可分資料時的係數爆衝(separation)。有時資料剛好被一條線完美分開,log-likelihood 會想把係數推到無限大。這不是你運氣好,是你要開始用 regularization 的訊號。
小心機三:不要只盯 accuracy。這句很老,但我還是要講,因為太多人被 99% accuracy 騙過,結果模型只是在猜多數類別。你至少要看 confusion matrix,然後再看 precision、recall、F1。
對了,講到這裡你會發現:我們其實一直在繞著「threshold」跟「成本」打轉。這才是現場。
工具指引:你如果想查 sklearn 這顆 LogisticRegression 到底有哪些 solver、正則化選項、multi_class 行為,直接去看 sklearn 的官方文件頁(就那頁,別找部落格轉述)。有時候你卡一整晚,答案就寫在參數表裡。
收尾純分享:下次你要延伸查資料,可以用關鍵字「logistic regression log-likelihood derivation」去挖推導,或直接搜「sklearn LogisticRegression solver saga liblinear lbfgs newton-cg」。那幾個詞一丟,線索就會自己跑出來。

