
說真的,你是不是也被一堆儀表板(Dashboard)搞瘋過?
今天要來聊聊一個我最近發現蠻有趣的現象。我們公司,或是說大部分公司吧,好像都得了「儀表板崇拜症」。什麼都要做成 Dashboard,產線稼動率、網站流量、銷售業績... 密密麻麻的圖表,看起來很專業,好像所有決策都有數據支撐。但老實說,你有沒有過這種經驗:你想查一個超級簡單的問題,例如「欸,上禮拜二下午,A產線停機最久的那台機器是哪台?」,結果你得打開三個儀表板,手動篩選日期、交叉比對,搞了半天比你直接走去產線問老師傅還慢。😅
這些儀表板,剛做好的時候很神,但很快就跟不上了。想加個新維度?「喔這個要請IT排程喔」。想問個儀表板上沒有的問題?「呃,這個可能要請數據團隊幫你撈一下資料」。久而久之,那些漂亮的圖表就變成一種「數位壁紙」,掛在那裡,好看,但真的要用的時候又覺得卡卡的。
如果... 我是說如果,跟數據庫互動可以像跟同事聊天一樣簡單呢?不用學什麼鬼東西、不用記一堆落落長的機器名稱,直接開口問,答案就跳出來。這就是我最近在研究的一個概念,原文叫 ChatFactory,但我喜歡叫它「數據聊天機器人」。
先說結論
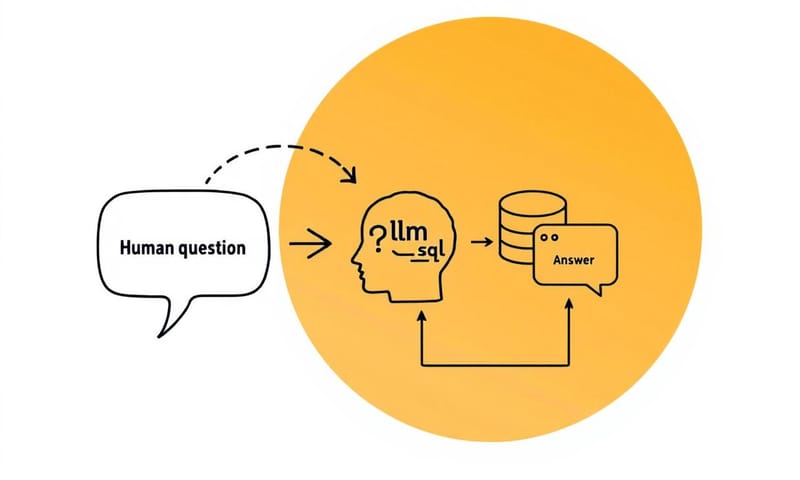
簡單講,ChatFactory 的核心概念就是用大型語言模型(LLM)當作你跟公司數據庫之間的「翻譯官」。你用白話文問問題,它自動幫你轉成電腦看得懂的 SQL 查詢語言,或是去翻說明文件,然後把答案用人話回給你。這樣一來,從產線上的作業員到高階主管,人人都能當數據分析師,再也不用被那些又硬又難用的儀表板綁架了。
它背後是怎麼玩的?其實沒那麼玄
這東西聽起來很神,但拆開來看,它的運作邏輯還蠻直觀的。主要就是靠兩個核心技術在跑。
第一個部分,就是處理跟「數據」有關的問題。你想想,你問「過去兩週,雷射切割機的總停機時間是多久?」這句話,它背後是怎麼運作的?
- 聽懂人話:首先,像 GPT-4 這種大型語言模型(LLM)會先理解你這句話的意思。它知道「過去兩週」是個時間範圍,「雷射切割機」是目標物件,「總停機時間」是你要計算的指標。
- 自動寫程式:接著,它會根據它對數據庫結構的理解(這個要先教它),自動生成一段 SQL 查詢語法。可能長得像這樣:
SELECT SUM(downtime_minutes) FROM machine_logs WHERE machine_name = 'Laser-Cutter-X500' AND event_timestamp >= NOW() - INTERVAL '14 DAY'; - 拿回答案:最後,它把這段 SQL 丟給數據庫去執行,拿到結果(比如說 631 分鐘),再用一句人話告訴你:「雷射切割機-X5 在過去兩週總共停機了 631 分鐘。」
整個過程你完全不用碰到任何一行程式碼,超方便。
第二個部分,是處理跟「文件」有關的問題。有時候你想找的不是數字,而是方法。像是「控制閥的標準作業流程是什麼?」或是「機台B-12亮紅燈了,怎麼辦?」
這時候就輪到另一個酷東西上場了,叫做Retrieval-Augmented Generation (RAG),中文可以翻成「檢索增強生成」。
所以...這跟傳統儀表板差在哪?
我自己是覺得,這不是要完全取代儀表板啦,而是補足了儀表板做不到的那些事。儀表板適合看「固定」的、宏觀的趨勢,但 ChatFactory 適合問「臨時」的、具體的問題。我弄了個比較表,你看完應該就懂了。
| 比較項目 | 傳統儀表板 (Dashboard) | 數據聊天機器人 (ChatFactory) |
|---|---|---|
| 提問彈性 | 很低。只能點選已經做好的篩選器跟圖表,想問新的問題?辦不到。 | 超高。想到什麼就問什麼,像跟真人對話一樣,問法模糊一點也沒關係。 |
| 使用門檻 | 說高不高,說低不低。要先搞懂每個圖表代表啥,在哪裡點選篩選。對了,你還得先登入系統。 | 幾乎是零。會打字聊天就會用。甚至可以串接到 LINE 或 WhatsApp,人在外面也能問。 |
| 客製化速度 | 慢到想哭。改個欄位、加個圖表,都要提需求、等 IT 排程、開會、測試... 搞不好一個月過去了。 | 超級快。大部分時候只要調整「系統提示詞 (System Prompt)」,幾分鐘就能搞定。下面會細講這個。 |
| 處理特定名稱 | 很龜毛。機器名稱「Laser-Cutter-X500」少打一個字都不行。 | 很聰明。你講「雷射切割機」、「那台切東西的」,它通常都能猜到你說的是哪一台。 |
| 適合場景 | 高階主管開會看大方向、監控核心 KPI。畫面一放出來,很有氣勢。 | 產線人員、維修工程師、倉管... 任何需要「立刻」拿到具體答案的人。 |

換個產業用,竟然只要改幾行字?
這大概是 ChatFactory 最讓我驚豔的地方:它的適應性。要把整套系統從「製造業」搬到「醫療業」或「零售業」,竟然不用重寫程式,只要改兩個地方就好。
第一個是前面提到的「系統提示詞 (System Prompts)」。這東西就像是給那個 LLM 翻譯官的一份「工作手冊」或「人設腳本」。你在裡面把規則寫清楚,它就會乖乖照辦。
例如,在製造業,你的 Prompt 可能會這樣寫:
你是一個製造業數據分析助理。你的任務是幫助使用者查詢產線數據。數據庫裡有幾個重要的表:[machine_status] 記錄了機台狀態跟停機時間、[inventory] 記錄了零件庫存、[production_orders] 記錄了生產工單... 當使用者問到「稼動率」,你就用公式 (總運轉時間 / 總工時) 去算...
但如果今天場景換到醫療業,你只要把這份「人設腳本」換掉:
你是一個醫療紀錄查詢助理。你的任務是協助醫護人員查詢病患資料。數據庫裡有幾個重要的表:[patient_records] 記錄了病患基本資料跟病史、[lab_results] 記錄了檢驗報告... 基於隱私,你絕對不能透露病患的身份證號碼或聯絡方式...
你看,核心的程式完全沒動,只是換了一份說明書,AI 的行為模式就完全不同了。真的蠻酷的。
說到這個,我就想到... 這種應用在不同國家的眉角就差很多。例如剛剛講的醫療業,在美國,他們有很明確的 HIPAA 法案來規範健康資訊的隱私跟安全,系統只要遵循那套規則走就好。但在台灣,我們的個資法、醫療法規對病歷資料的串接跟存取有更嚴格的限制,要導入這種聊天查詢系統,法遵那關肯定要花更多時間去釐清,不是技術搞定就好。這點很重要,千萬記得。
第二個要改的地方就更單純了,就是資料庫的連線設定檔。換個 IP、使用者名稱、密碼,就好了。根本是小菜一碟。
好,該潑冷水了:這東西有哪些坑?
吹了半天,也該平衡報導一下。老實說,這東西不是萬靈丹,導入時有好幾個坑,你要是沒注意到,它可能比原來的儀表板更難用。我自己是覺得,至少有下面這幾點要特別小心:
- Garbage In, Garbage Out (垃圾進,垃圾出)
這是數據科學的黃金定律,在這裡也一樣。如果你的公司從一開始就沒有好好記錄數據,資料亂七八糟、缺東缺西,那 AI 再怎麼聰明也沒用。它只會跟你說「抱歉,查不到相關資料」。所以,想用這個,第一步是先把數據治理做好。 - System Prompt 寫不好,AI 就變智障
前面說改 Prompt 很簡單,但「簡單」跟「做好」是兩回事。如果你的 Prompt 寫得模稜兩可,或是忘了描述某個重要的欄位,那 LLM 就會開始「腦補」,產出錯誤的 SQL 或給你一個鬼扯的答案。這需要一點 prompt engineering 的技巧跟反覆測試。 - 資料庫一改版,馬上就出事
這個超寫實。你想想,你公司的DBA(數據庫管理員)哪天心血來潮,為了優化效能,把 `machine_status` 這個資料表名稱改成 `machine_state`。如果他沒跟你說,你也忘了去更新 System Prompt... 那恭喜你,你的 ChatFactory 馬上就殘廢了,問什麼都跟你說「聽不懂」。所以導入後的維護流程很重要。 - 文件品質決定了 RAG 的上限
如果你想用 RAG 來做故障排除,但你公司的操作手冊是十年前寫的,內容過時、錯誤百出... 那 AI 也只會學到一堆垃圾。它只會把那些過時的錯誤資訊,用看起來很專業的口氣再講一次給你聽。所以,知識庫本身的品質才是根本。 - 信任感是個大問題
對很多習慣看圖表的人來說,一個冷冰冰的聊天機器人丟出一句「答案是 47 個」,他們心裡會犯嘀咕:「真的假的?你怎麼算的?會不會騙我?」所以初期最好能有個「顯示 SQL 語法」或「提供資料來源」的功能,讓大家可以驗證,慢慢建立信任感。
所以,這東西到底值不值得導入?
我自己是覺得,這完全取決於你的團隊現在最大的痛點是什麼。
如果你的公司已經有很成熟、運作良好的儀表板,大家也都用得很習慣,那或許沒那麼急迫。但如果你常常聽到有人抱怨「又要等IT撈資料」、「這個儀表板怎麼那麼難用」、「我想查個東西搞半天」,那這類型的「數據聊天機器人」絕對會是你的救星。
它不會完全取代儀表板,儀表板在視覺化呈現宏觀趨勢上還是有不可替代的地位。但 ChatFactory 更像是一個敏捷、聰明、隨傳隨到的「數據小助理」,它把數據分析的權力,從少數技術人員手上,真正還給了每一個需要資訊做決策的人。
我覺得這才是 "data-driven" 真正的意義吧,不是掛一堆漂亮的圖表在那裡,而是讓數據真的在組織的每個角落「流動」起來。
聊了這麼多,換你說說看!在你公司,你覺得是哪個部門或哪個角色,最需要這種聊天機器人來解決問題?是每天要處理一堆鳥事的產線主管、在倉庫裡跑來跑去的倉管人員,還是常常要臨時報告的管理層?在下面留言分享你的看法吧! 👇


