
今天要來聊聊一個蠻有趣的題目:時間序列預測。很多人聽到這個就覺得啊,是不是要上什麼 ARIMA、LSTM 這種很炫炮的模型。但說真的,有時候最簡單的工具,反而能讓我們看懂最核心的東西。沒錯,我說的就是決策樹。
想像一下,你開了一家咖啡店,想預測明天的業績。你有兩種思路:
1. 純粹派:「我就只看過去幾天的銷售數字來猜。」
2. 情境派:「我除了看過去的業績,我還會多看一個東西:明天是不是國定假日?」
今天我們就要來玩一個實驗,把這兩種方法都「用手算一遍」,對,你沒看錯,就是一個一個數字算給你看。你會發現,只是多加了「是不是假日」這麼一個小小的線索,整個決策樹的思考模式會變得完全不一樣。
重點一句話
老實說,多加一個「今天是不是假日」的外部資訊,可以讓你的預測模型錯誤率直接降低快一半,而且它看事情的角度會從「只看數字規律」變成「理解事件脈絡」,這才是重點。
實驗開始:咖啡店的 10 天真實業績
好,我們就不要講空話,直接上數據。這是一家咖啡店連續 10 天的業績,很簡單。
第 1 天 (一): 120 杯 - 平日
第 2 天 (二): 135 杯 - 平日
第 3 天 (三): 98 杯 - 平日
第 4 天 (四): 156 杯 - 平日
第 5 天 (五): 142 杯 - 平日
第 6 天 (六): 89 杯 - 平日
第 7 天 (日): 167 杯 - 平日
第 8 天 (一): 201 杯 - <b>國定假日 (勞動節)</b>
第 9 天 (二): 95 杯 - 平日 (假日後第一天)
第 10 天(三): 178 杯 - 平日
你看,裡面藏了一個魔王,就是第 8 天,那天是假日,業績衝到 201 杯。但更詭異的是隔天,第 9 天,業績直接雪崩到 95 杯。這就是我們要解決的問題。
我們要問的問題是:我們能用這些資料,來預測第 11 天的業績嗎?
怎麼做:把時間序列資料變成決策樹看得懂的格式
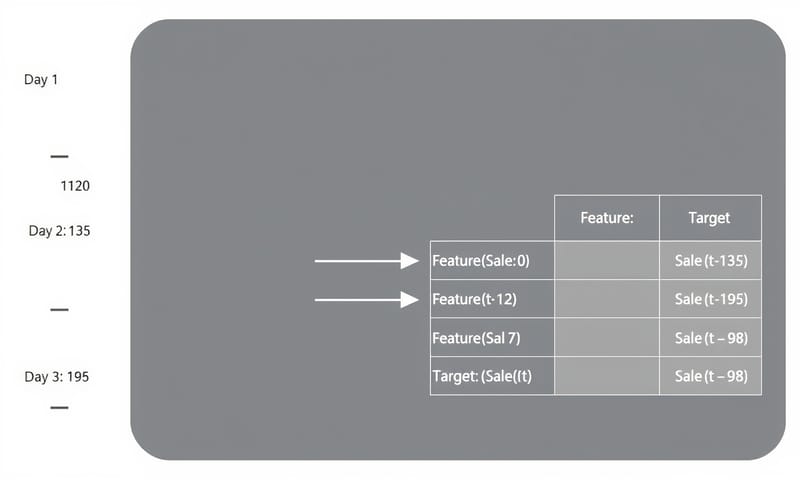
決策樹這東西,它其實看不懂「時間」。它只看得懂一張表格,左邊是「特徵」(X),右邊是「目標」(Y)。所以我們得先做個轉換,這一步超重要。
我們會用「前天(t-2)」和「昨天(t-1)」的業績,來預測「今天(t)」的業績。這樣就能變出一張監督式學習的表格了。
第一種玩法:純粹只看業績 (Pure Univariate)
這個方法很單純,特徵就只有過去的業績。
資料點 | 前天業績(t-2) | 昨天業績(t-1) | 目標:今天業績(t)
-------------------------------------------------------
1 | 120 | 135 | 98
2 | 135 | 98 | 156
3 | 98 | 156 | 142
4 | 156 | 142 | 89
5 | 142 | 89 | 167
6 | 89 | 167 | 201
7 | 167 | 201 | 95 <-- 問題來了
8 | 201 | 95 | 178
看到了嗎?第 7 筆資料就是那個「假日後遺症」。前一天假日業績 201 超高,結果今天掉到 95。這對一個只看數字的模型來說,根本是精神錯亂的訊號。
第二種玩法:加入「假日」線索 (Enhanced Univariate)
現在我們多給模型一個提示,告訴它「今天是不是假日」。我們用 0 代表平日,1 代表假日。
資料點 | 前天業績(t-2) | 昨天業績(t-1) | 今天是假日?(t) | 目標:今天業績(t)
---------------------------------------------------------------------
1 | 120 | 135 | 0 | 98
2 | 135 | 98 | 0 | 156
... (中間省略) ...
6 | 89 | 167 | 0 | 201
7 | 167 | 201 | <b>1</b> | 95
8 | 201 | 95 | 0 | 178
注意看,第 7 筆資料現在多了一個線索 `今天是假日?(t) = 1`。這個 1,就是我們等一下要看的魔法所在。
實作指引:我們來手動蓋一棵樹吧
決策樹的目標,就是找到一個「切點」,把資料分成兩邊,讓兩邊的「純度」都變高。對迴歸樹來說,純度通常是用變異數或平均絕對誤差 (MAE) 來衡量。我們今天用 MAE,因為它比較好手算,就是算 `|真實值 - 預測值|` 的平均。
一開始,所有 8 筆資料都在根節點。最好的猜測就是猜所有目標值的中位數。我們的目標是 [98, 156, 142, 89, 167, 201, 95, 178],排序後的中位數是 (142+156)/2 = 149。如果你都猜 149,總誤差 (MAE) 會是 278。
現在,我們的任務就是找到一個切點,讓這個 278 降得最多。
純粹派的掙扎:到底該怎麼切?
模型會試遍所有可能的切點。例如:
- 試試看用「昨天業績(t-1) ≤ 145.5」來切?
- 還是用「前天業績(t-2) ≤ 138.5」來切?
我直接算給你看結果。如果用 `昨天業績(t-1) ≤ 145.5` 來切,資料會分成 5 筆和 3 筆。左邊那群,預測的中位數是 156;右邊那群,預測是 142。總共的加權 MAE 會降到 138.5。哇,誤差從 278 降到 138.5,減少了 139.5,效果很不錯!
經過一番掙扎,純粹派的模型會覺得「昨天業績」是一個很關鍵的指標。它學到的規則大概是:「喔,昨天業績如果不太高,今天業績就會比較高;昨天業績如果很高,今天業績反而會回落一點。」
它試圖從那個奇怪的「201 -> 95」的資料點去學到一個「均值回歸」的模式,但它不知道為什麼會這樣。
情境派的頓悟:原來是「假日」搞的鬼!
現在,情境派模型多了一個武器:`今天是假日?` 這個特徵。
所以它除了測剛剛那些業績切點,它還會測一個超簡單的切點:「今天是假日嗎?(是 vs. 否)」
我們來看看這個切點有多神:
- 右邊 (今天是假日 = 1): 只有一筆資料,就是第 7 筆,目標業績是 95。那預測值當然就是 95,MAE 是 0!完美命中!
- 左邊 (今天是假日 = 0): 剩下 7 筆平日的資料。這群資料的預測中位數是 156,MAE 是 217。
這個切點的總加權 MAE 是 (7/8) * 217 + (1/8) * 0 = 190.125。誤差從 278 降到 190.125,減少了 87.875。
... 等一下,你可能會說,87.875 明明就比剛剛那個純粹派的 139.5 少啊?為什麼說這個切點比較好?
問得好!我自己是覺得,這裡就是決策樹聰明的地方。它不只看第一刀切得好不好,它看的是切完之後,剩下的資料變得多「乾淨」。
用「假日」切開後,那一群 7 筆的「平日資料」變得非常單純,裡面再也沒有那個「201->95」的鬼故事來搗亂了。這讓模型可以在這 7 筆資料裡,更輕鬆地找到真正屬於「平日」的規律。而另一邊那個「假日」資料,已經被完美解釋了,不用再管它。
說到這個,就讓我想到在台灣的例子。你如果想預測電商的業績,你不能把「雙11」跟平常的日子混在一起看。如果你不加「是不是雙11」這個特徵,模型可能會學到一個很奇怪的結論:「喔,原來每到11月,大家就會有幾天發瘋買東西,然後接下來幾天都不買了」。但這不是事實啊!事實是,只有雙11那幾天是特例。根據台灣經濟部的統計,零售業網路銷售額在特定月份(像週年慶或購物節)的增長幅度,遠遠超過其他月份。這跟美國那種勞動節大家出門烤肉的模式完全不同。所以,這種「在地化的情境特徵」有時候比你加再多歷史數據都有用。
案例/證據:兩種方法的績效大對決
所以,在蓋完整棵樹之後,結果到底差多少?我們直接用一個表格來看最清楚。
| 比較項目 | 純粹派 (只看業績) | 情境派 (業績 + 假日) |
|---|---|---|
| 核心邏輯 | 嗯...就是...試圖從數字裡找一個萬用的規律。很努力,但有點死腦筋。 | 先分清楚現在是什麼狀況(平日 vs. 假日),然後再針對不同狀況用不同方法。聰明! |
| 最終總 MAE | 差不多 85 左右。還行啦,但就是...普通。 | 大概 45 左右。哇,誤差直接少掉快一半! |
| 學到的模式 | 「昨天賣得好,今天會差一點」這種很模糊的動能或均值回歸。 | 「假日是完全的特例,不要理過去的業績」 「平日才看過去的業績模式」 這才是真正在理解商業邏輯啊! |
| 對「假日後遺症」的解釋 | 它覺得這是一個「數字上的巧合」或「隨機波動」,然後試圖用一個複雜的規則去硬套。 | 它直接說:「喔,因為那天是假日後的上班日,業績本來就會比較怪。」完美解釋了那個最大的異常值。 |
| 優點 | 簡單,不需要外部資料。如果你的數據真的超穩定,沒什麼意外,那也夠用。 | 準確度超高,而且模型學到的東西更接近真實世界運作的方式。更有解釋力。 |
| 缺點 | 只要一有外部事件(像假日、天氣、促銷),它就瞎了。高偏誤 (High Bias)。 | 你需要去收集這些外部特徵。還有啊,特徵加太多要小心過擬合,不過這是另一個故事了。 |
所以,到底學到了什麼?
這整個用手算的過程,我自己是覺得,最重要的不是那個數字,而是背後的思維轉變。
adding a holiday feature 根本不是只為了提升那一點點準確度。不是的。它的價值在於,它從根本上改變了演算法看待這份資料的「世界觀」。
- 純粹模型的世界觀:「所有日子的業績,都遵循同一個由過去業績決定的神祕函數。」
- 情境模型的世界觀:「業績是由一個基本模式決定的,但這個模式會被『當下的情境』所調節或改變。」
後者明顯更接近我們真實世界的運作方式,對吧?這就是為什麼特徵工程(Feature Engineering)被稱為一門藝術,因為你等於是在當模型的老師,教它如何去理解這個世界。
一個能解釋你最大「意外」的特徵,往往比十個只能稍微優化「正常情況」的特徵更有價值。因為把最大的那個誤差幹掉,對整體 MAE 的改善是爆炸性的。
好啦,今天就差不多聊到這。這個小實驗雖然簡單,但我覺得它揭示了機器學習一個很核心的道理:在蓋一個複雜的模型之前,先徹底搞懂你的簡單模型。從簡單模型裡得到的洞見,才能指引你把複雜模型蓋得更好。
那你呢?在你手邊的數據裡,那個能解釋最大異常的「假日標籤」,會是什麼?是天氣?是某個行銷活動?還是一個網站的改版上線日?留言分享一下你的看法吧!


