
嗯... 機器學習。最近一直在想這個東西。
以前的電腦,就是你叫它做什麼,它就做什麼。一步一步,寫得很死。但現在不一樣了... 我們開始餵給電腦一大堆資料,然後,很神奇的是,它自己開始找出我們從來沒發現過的規律。
這大概就是機器學習(Machine Learning)的核心概念吧。不是教它規則,是讓它從經驗中自己「學會」規則。
所以,電腦是怎麼「學」的?
想像一下... 你在教一隻狗撿球。一開始你把球丟出去,牠可能傻傻地看著你。但你示範幾次,撿回來就給牠零食,牠就慢慢懂了。下一次,牠會做得更好。機器學習... 說真的,就是這麼一回事,只是對象從狗換成了電腦。
我們給它看超多範例,它就自己去歸納、去找出模式。整個過程很像... 一個很會舉一反三的學生。
在聊這個的時候,會一直聽到兩個詞:特徵 (Features) 跟標籤 (Labels)。
- 特徵 (Features):嗯... 就是用來描述一件事情的各種屬性。比方說,我們要判斷一張圖是不是貓,那「有爪子」、「有鬍鬚」、「尖耳朵」這些就是特徵。
- 標籤 (Labels):這就是正確答案。以上面那個例子來說,「是貓」或「不是貓」,這個結論就是標籤。
所以,整個學習過程,就是讓機器去看一大堆有「特徵」跟「標籤」的資料,然後自己找出這兩者之間的關聯。比如說,它看了十萬張圖之後,可能會得出一個結論:「嗯,通常有鬍鬚又有尖耳朵的,『是貓』的機率很高。」
訓練跟測試,就像學校考試
拿到資料後,不是全部都丟給機器去學。我們會把它們分成幾份,這很重要。
主要就是「訓練集」跟「測試集」。
- 訓練集 (Training Set):這是給模型(Model,我們通常不叫電腦,叫模型)看的課本跟習題。它會從這裡面去學習所有知識。
- 測試集 (Test Set):這是模擬考的考卷。裡面的題目,模型在「讀書」的時候完全沒看過。用這個才能知道,它到底是真懂了,還是只是把課本背起來而已。
你想想,如果拿上課教過的例題一模一樣地去考試,那根本測不出學生的程度,對吧?所以用「沒見過的新資料」去測試,才能知道這個模型到底有沒有用。
有時候... 還會切出一個叫「驗證集 (Validation Set)」的東西。這個比較像... 平常的小考。在整個漫長的訓練過程中,用來隨時看看學習狀況好不好,需不需要調整讀書方法。可以幫忙避免下面會提到的「過擬合」或「欠擬合」。

學習路上最常見的兩個坑:過擬合與欠擬合
模型在學習的時候,很容易走偏。最常見的兩個問題,就是「過擬合」跟「欠擬合」。
過擬合 (Overfitting)
這個超常見。簡單說,就是「書讀得太死了」。
它把訓練資料裡的所有細節,甚至是無關緊要的雜訊,全都死背下來。結果就是,在訓練集上表現超好,準確率可能 99%,但一碰到沒見過的測試資料,就錯得一蹋糊塗。
這就像一個學生,把考古題的每一題、每一個字都背得滾瓜爛熟。只要考題一模一樣,他能拿滿分。但只要題目稍微換個數字、改個問法,他就完全不知道怎麼辦了。因為他根本沒理解背後的概念,他只是在「記憶」,而不是在「學習」。
欠擬合 (Underfitting)
這剛好相反,就是「根本沒讀進去」。
模型太過簡單,或是訓練得不夠久,導致它連最基本的規律都沒抓到。結果就是在訓練集上表現很差,在測試集上... 當然也一樣爛。
這就像學生連課本都沒翻幾頁就上考場。不管是考課本習題還是全新的題目,他都不會寫。

說到這個,要避免模型「假裝學會」,有個叫交叉驗證 (Cross-Validation) 的技巧。我自己是覺得這方法蠻聰明的。它不是只把資料分成「一份」訓練集和「一份」測試集,而是分成好幾份,例如五份。然後輪流,拿其中一份當測試集,另外四份當訓練集,這樣重複做五次。最後再把五次的表現平均一下,這樣得出來的評估結果,會比單一次的測試要可靠得多,比較不會因為運氣好、剛好抽到簡單的考題而產生誤判。
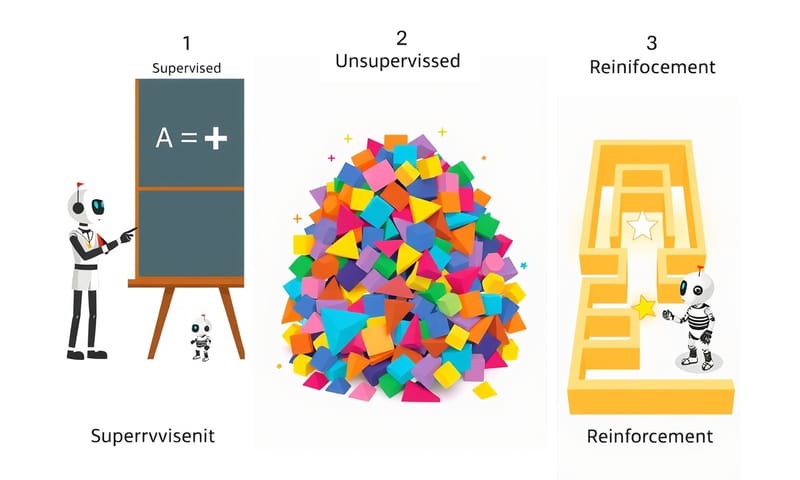
機器學習主要有三種學派
好,概念差不多了。那實際上,機器學習有哪些做法?主流大概分成三種,他們的「教學風格」差很多。
- 監督式學習 (Supervised Learning)
- 非監督式學習 (Unsupervised Learning)
- 強化式學習 (Reinforcement Learning)
這三種的邏輯,我自己是覺得用一個表格來想,會清楚很多。
| 學習方式 | 教學方法 | 需要什麼資料 | 白話比喻 |
|---|---|---|---|
| 監督式學習 (Supervised) |
給它題目也給它「標準答案」。 | 已經標記好的資料。 (例如:這張是貓、那張是狗) |
就像有個家教,帶著你一題一題做練習題,告訴你對錯。 |
| 非監督式學習 (Unsupervised) |
只給它一堆資料,不給答案,叫它自己看著辦。 | 未經標記的資料。 (例如:就一堆顧客的購買紀錄) |
像整理一個超亂的房間,你不知道東西該分幾類,但你會把看起來像的擺在一起。 |
| 強化式學習 (Reinforcement) |
不直接教,讓它自己去試。做對了給獎勵,做錯了就沒獎勵。 | 不需要預先準備的資料集,而是透過跟「環境」互動來產生資料。 | 訓練寵物。做對指令給零食(獎勵),牠就會越來越常做那個動作。 |
監督式學習是目前最普遍、應用也最廣的。你給它大量的「問題和答案」,它學會怎麼從問題去預測答案。最有名的例子就是 Google 翻譯,它就是看了網路上億萬個已經翻譯好的句對,才學會中翻英的。在台灣,這也用在很多地方,像是銀行的信用卡盜刷偵測,或是用 AI 判斷農產品的品質,之前農委會好像就有在推類似的計畫。
非監督式學習就比較像在探索。你不知道你想找什麼,但你相信資料裡一定有什麼模式。最常見的就是顧客分群,電商網站把你看起來消費習慣差不多的客人自動圈在一起,然後推播同樣的廣告給你們。或是新聞網站,把內容類似的文章自動聚類,變成一個專題。
強化式學習... 這個就更酷了,它比較像在學一個「策略」。最有名的例子就是 AlphaGo。沒有人教它棋譜,它就是透過不斷跟自己下棋,贏了就給自己「獎勵」,輸了就「懲罰」,幾百萬盤之後,它就自己悟出了比人類更強的下棋策略。現在很多自動駕駛或機器人控制,背後都有它的影子。
所以... 新手該從哪裡開始?
老實說,絕大部分的商業應用,一開始碰到的都會是「監督式學習」。因為通常我們手上的問題都很明確,例如「預測下個月的銷量」(這叫迴歸 Regression),或是「判斷這封 email 是不是垃圾郵件」(這叫分類 Classification)。
所以如果你是剛入門,想找個方向鑽研,先把監督式學習的幾個基本模型搞懂,像是線性迴歸 (Linear Regression) 或邏輯迴歸 (Logistic Regression),會是比較實際的路。這些是基礎中的基礎,但已經能解決很多問題了。
非監督式和強化式學習... 比較像進階課題,通常用在更複雜或更開放的場景。當然也很有趣,但可以當作下一步。
說到底,機器學習就像是給了電腦一雙會學習的眼睛。它看到的世界,有時候跟我們人類看到的很不一樣。有時候它找出的規律會讓你覺得「啊,原來是這樣!」,有時候又會讓你覺得「這機器到底在想什麼?」。
我覺得... 這就是這領域最迷人的地方吧。
這三種學習方式,你覺得哪一種最有趣?或是有在生活中看過什麼讓你印象深刻的機器學習應用嗎?在下面留言聊聊吧!


