
今天來聊聊 AI。嗯...更準確地說,是 AI 的「不可靠」問題。
跟 LLM 玩過的人都知道那個痛。你精心寫好一個 prompt,要求五個 key 的 JSON。結果它回你一段廢話。你叫它遵守三條規則,它很自信地只做了兩條。這東西,做 demo 蠻酷的,但真的要做成產品...很難。
重點一句話
與其教 AI「感覺對了」,不如給它一張「檢查清單」。這是 Apple 最近一篇論文的核心,叫 RLCF。我覺得這想法...很務實。把一個模糊的美學問題,變成了可以驗證的工程問題。
AI 調教,靠人力回饋就夠了嗎?
之前大家都在喊 RLHF (Reinforcement Learning from Human Feedback),就是靠人去標註哪個答案比較「好」,然後讓模型去學。ChatGPT 就是這樣變聰明的。但這方法,說真的,又貴又慢,而且很主觀。你覺得好,我可能覺得不行。
這就像...你請人評價一幅畫。大家會給出感覺,但沒辦法給出「修改指南」。
Apple 這篇論文,全名是《Checklists Are Better Than Reward Models For Aligning Language Models》,它提出的 RLCF (Reinforcement Learning from Checklist Feedback) 就不一樣了。它不問「哪個比較好?」,它問「這份產出,有沒有完成清單上的每一項?」。
一個是問感覺,一個是逐項打勾。差別很大。
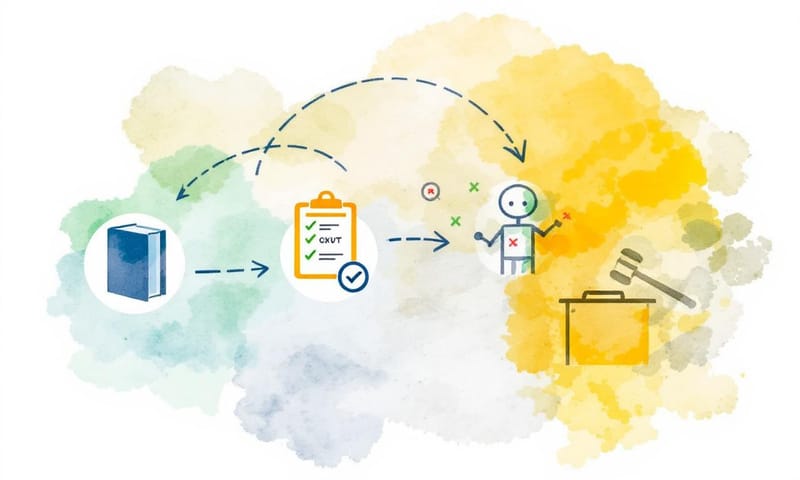
怎麼做?三個角色一台戲
整個流程大致是這樣,他們用了三個模型:
- 老師模型 (Teacher):通常是個更強的模型,比如 GPT-4。它的任務是讀懂你的原始 prompt,然後生成一份非常詳細的「檢查清單」。
- 學生模型 (Student):這是我們要訓練的主角。它去嘗試回答原始 prompt。
- 裁判模型 (Judge):裁判會拿著老師出的清單,一項一項去檢查學生的答案。完成就打勾,沒完成就打叉。
最後,學生模型會根據這份「成績單」去微調自己。它不是學著「討人喜歡」,而是學著「把清單上的事做完」。這 feedback 超級具體。
老實說,這方法真的很聰明。它把最貴的人力環節,用一個強大的模型(老師和裁判)給自動化了。成本和效率,應該差很多。
RLHF vs. RLCF,到底差在哪?
我自己是覺得,可以這樣想。做個簡單的對比。
| 比較項目 | 傳統 RLHF (人力回饋) | 新的 RLCF (清單回饋) |
|---|---|---|
| 回饋標準 | 很主觀。看標註員當下的感覺,有點像藝術鑑賞。 | 很客觀。清單上有沒有做到,對就是對,錯就是錯。 |
| 回饋粒度 | 很粗。通常就是「A 比 B 好」這樣一個總分。 | 很細。告訴你第 1、3、5 項對了,但第 2、4 項錯了。 |
| 成本與速度 | 極度依賴昂貴且緩慢的人工標註。很花錢。 | 用模型自動生成清單和評分,速度快,規模化也更容易。 |
| 最終目標 | 讓模型產出更「討喜」、更符合「大眾偏好」的內容。 | 讓模型產出更「可靠」、更符合「明確規則」的內容。 |
風險與應變:清單不是萬靈丹
不過呢,這方法也不是完美的。我在想幾個問題。
首先,如果「老師模型」自己就理解錯了 prompt,那它開出來的清單本身就是錯的。垃圾進,垃圾出。源頭就歪了,後面再怎麼對齊也沒用。
再來,「裁判模型」也不一定 100% 公正。它也是個 AI,也可能有自己的偏見或理解盲點。如果裁判判錯了,學生就會學到錯誤的東西。
這也讓我想到台灣這邊的情況。像工研院 (ITRI) 之前在談論 AI 導入製造業,他們更關心的是工業場景的「信賴 AI (Trustworthy AI)」。那裡的「清單」就不是翻譯或寫作,而是像「機械手臂操作是否符合安全規範」、「感測器數據是否在誤差範圍內」。這種 checklist 的正確性,攸關產線安全,要求比寫個旅遊計畫嚴格多了。所以,Apple 這個方法雖好,但 checklist 的品質和驗證,才是真正的核心難點。這點跟我們在台灣看高科技製造業的導入,思路其實是相通的,只是場景不同。
現在能怎麼用?在應用程式層強制執行
我們小團隊或個人開發者,當然不可能真的去跑一套 RLCF 訓練流程。太複雜了。
但這個「清單」精神,現在就能用。核心就是:用結構化的 Schema 來驗證輸出。
Python 有個叫 `pydantic` 的庫就超適合做這件事。你可以先定義好你想要的資料結構,等於是手動寫好一張 checklist。
原文裡那個用 `instructor` 搭配 `pydantic` 的例子就很好。簡單講,就是你用 `pydantic` class 定義了一個 `TravelItinerary` 的模型,裡面規定了必須要有 `city`、`days`,還有一個 `itinerary` 列表,列表裡每項都要有活動、地點、時間...
# 這段是概念示意,展示 Pydantic 如何當作 checklist
from pydantic import BaseModel, Field
from typing import List
# 這就是你的 checklist
class ItineraryItem(BaseModel):
activity: str = Field(..., description="具體活動")
location: str
start_time: str
end_time: str
class TravelItinerary(BaseModel):
city: str
days: int
# 這裡用 Field 強制規定 itinerary 至少要有一項
itinerary: List[ItineraryItem] = Field(..., min_items=1)
# 然後你會用一個像 instructor 這樣的庫
# 告訴 OpenAI API:你的回答必須符合 TravelItinerary 這個格式
# 如果不符合,instructor 會自動處理錯誤,甚至重試
# prompt = "幫我規劃一個兩天的東京科技美食之旅"
# response = create_itinerary(prompt) # 假設 create_itinerary 內部用了 instructor
這段 code 雖然沒有真的去 fine-tune 模型,但它在應用程式層強制執行了你的 checklist。如果 LLM 回來的東西格式不對,`pydantic` 會直接報錯。有些工具庫(像 `instructor`)甚至會自動拿著錯誤訊息,叫 LLM 再試一次,直到它給你正確的格式為止。
這招...對,就是個治標不治本的 hack,但超實用。至少能保證你收到的資料是乾淨、可用的。
所以,可靠的 AI 能做什麼新東西?
一旦 AI 的輸出變得可靠,很多以前想做但不敢做的 App 就有機會了。
- 絕對不出錯的旅遊規劃器:航班號、飯店地址、訂位代碼... 每個細節都必須正確。用 checklist 來確保。
- 合規的報告生成器:給金融或法務用的。自動生成報告,並保證所有需要的章節、免責聲明、數據格式都符合法規。
- 自動化工作流程工具:比如新人 on-boarding。自動發 email、加到 Slack、開權限... 每個步驟都透過 checklist 確認完成,不會漏掉。
我自己覺得,這思路很有用。它讓我們從不斷地「求」AI 做好,變成我們可以「要求」AI 做好。
雖然離真正的「對齊」還有很長的路,但至少,這給了我們開發者一個可以抓在手上的工具。一個更工程、更務實的工具。
不知道你怎麼看?除了旅遊和報告,你覺得這種「清單式 AI」還能用在哪個最讓你頭痛的場景?留言分享一下吧。


