
今天要來聊聊 Python 效能優化。老實說,我以前也覺得 Python 就是慢,寫起來是蠻爽的啦,但跑起來就...嗯,你懂的。語法糖的代價嘛。直到我真的踢到鐵板,那是在一個要處理好幾 GB 資料的專案上,客戶還要求反應要夠即時。那時候我才領悟到,Python 本身不是問題,有問題的是我的寫法。🤣
幫你畫重點
Python 一點都不慢,是你寫的方法讓它變慢了。而且,拜託,優化的第一步絕對是先找出「真正慢的地方」,而不是憑感覺瞎忙一通。
第一步,也是最重要的一步:先測速,再說要跑多快
我發誓,我早期犯過最蠢的錯,就是「我猜」這裡可能很慢。然後花一堆時間改,結果效能根本沒差。後來學乖了,一定要用 Profiler(分析器)這種工具。它每次都會給我驚喜,瓶頸常常都出現在我意想不到的鳥地方。
Python 內建的 `cProfile` 就超好用。你可以把它想像成一個碼錶,但它不是只記總時間,而是幫你記下程式裡每個函式分別花了多少時間。一跑下去,哪個函式是害群之馬,馬上現形。
import cProfile
import pstats
# 假設這是一個超級無敵複雜又慢的計算
def heavy_task():
total = 0
# 跑個一千萬次,故意讓它慢
for i in range(10_000_000):
total += i * 2 % 3
return total
def main():
# 用 cProfile 把整個執行過程包起來
with cProfile.Profile() as profile:
heavy_task()
# 跑完之後,把結果印出來看看
stats = pstats.Stats(profile)
# 根據「累計時間」排序,只看最慢的 10 個
stats.sort_stats(pstats.SortKey.TIME).print_stats(10)
if __name__ == "__main__":
main()你看,跑完上面這段,它就會清清楚楚告訴你 `heavy_task` 這個函式佔了幾乎 100% 的時間。雖然這個例子很廢,但真實世界裡,你可能會發現最慢的根本不是你以為的複雜演算法,反而是某個不起眼的檔案讀取或資料轉換。千萬記得,沒有測量,就沒有優化。

隨手可做的基本功:幾個馬上讓你有感的技巧
找到瓶頸之後,就可以開始動手術了。但通常不用動什麼大刀,改幾個小習慣,效能就飛起來了。這些是我覺得投資報酬率最高的幾個方法。
1. 別再自己寫迴圈了,多用內建函式
以前我也很愛自己寫 `for` 迴圈來做加總或找最大值。但後來發現,Python 的內建函式像是 `sum()`、`max()`、`min()` 這些,天啊,它們底層都是用 C 語言寫的,速度快到不行。你自己用 Python 寫的 for 迴圈根本看不到它的車尾燈。
import time
data = list(range(1_000_000))
# 方法一:手動迴圈
start = time.perf_counter()
total = 0
for i in data:
total += i
print(f"自己寫迴圈: {time.perf_counter() - start:.4f} 秒")
# 方法二:內建函式
start = time.perf_counter()
total = sum(data)
print(f"用內建 sum(): {time.perf_counter() - start:.4f} 秒")
# 跑出來可能差了好幾倍,超扯2. 挑對「容器」比什麼都重要:List vs. Set/Dict
這點真的、真的很重要!我遇過一個案子,要從幾百萬筆資料裡面,不斷檢查某個 ID 是不是存在。一開始很自然就用 `list` 存,結果程式慢到懷疑人生。後來只是把 `list` 換成 `set`,就...就順了。從幾秒鐘變成幾乎是瞬間完成。
簡單講,`list` 就像一本沒有目錄的書,你要找一個東西,得從第一頁翻到最後一頁。資料越多,找越久。但 `set` 或 `dict` 就像一本有超級詳細索引的書,你報上名字(key),它「咻」一下就告訴你在哪,速度不會因為書有多厚而變慢。這在電腦科學裡叫 O(n) 跟 O(1) 的差別,但我自己是覺得「翻書」的比喻好懂多了。
import time
# 準備千萬級別的資料
items_list = list(range(10_000_000))
items_set = set(items_list)
lookups = [5_000_000, 9_999_999, 123456] # 隨便挑幾個數字來找
# 在 list 裡面找
start = time.perf_counter()
for val in lookups:
_ = val in items_list
print(f"用 List 找: {time.perf_counter() - start:.4f} 秒") # 會很慢...
# 在 set 裡面找
start = time.perf_counter()
for val in lookups:
_ = val in items_set
print(f"用 Set 找: {time.perf_counter() - start:.4f} 秒") # 幾乎是 0 秒3. 用 Comprehension 取代 For 迴圈 appending
List/Dict Comprehension(列表/字典生成式)不只是看起來比較潮、程式碼比較短。它的執行效率也比你寫一個 `for` 迴圈然後一直 `.append()` 還要快。原因跟前面一樣,它底層的運作更接近 C 的速度。
4. 字串相加的無底洞:改用 `join`
這是一個超級隱密的效能殺手。在迴圈裡面用 `+` 來串接一堆小字串,會產生一大堆不必要的暫時字串物件,記憶體會被搞得很亂,速度也會被拖垮。正確的做法是,先把所有小字串搜集到一個 `list` 裡面,最後再一次用 `"".join(list)` 把它們合起來。速度差非常多!
當資料大到裝不下:進階武器庫
如果上面那些基本功都做了,程式還是慢,或記憶體直接爆掉,那就要出動一些更厲害的工具了。
記憶體救星:Generator (產生器)
如果你要處理一個 10GB 的 Log 檔,你總不會想把它整個讀進記憶體吧?電腦肯定直接罷工。這時候就要用 Generator。它是一種「惰性求值」(Lazy Evaluation) 的技巧,意思就是「要用的時候我才生給你」。它不會一次把所有資料讀進來,而是一次只讀一行(或一個單位),處理完,再讀下一行。這樣不管檔案多大,記憶體佔用都非常小。
# 這個函式不會一次讀完檔案,它會回傳一個 generator
def read_large_file_generator(path):
with open(path, 'r') as f:
for line in f:
# yield 這個關鍵字就是魔法所在
yield line.strip()
# 就算 "huge_log_file.txt" 有 50GB,記憶體也沒事
# for 迴圈每次只會跟 generator 要一筆資料來處理
for log_entry in read_large_file_generator("huge_log_file.txt"):
if "ERROR" in log_entry:
print(log_entry)
對了,突然想到,List Comprehension 也有 Generator 版本,只要把 `[]` 改成 `()` 就行了。例如 `(i for i in range(1000000))`,它不會立刻產生一百萬個數字,而是變成一個等你來拿的 Generator,超實用。
重複計算的救星:`lru_cache`
你有沒有寫過一種函式,給它相同的輸入,它永遠会回傳相同的結果,但這個計算過程本身很慢?例如,去 call 一個外部 API,或是做一些複雜的數學運算。這時候 `lru_cache` 就跟神一樣好用。
你只要在函式定義上面加一個 `@lru_cache` 的裝飾器,Python 就會自動幫你把「輸入」跟「結果」記下來。下次你用同一個輸入再 call 它一次,它根本不會真的去執行函式裡面的慢程式,而是直接從快取把上次的結果丟回來給你。根本是免費的午餐!
from functools import lru_cache
import time
# maxsize=None 代表快取沒有上限
@lru_cache(maxsize=None)
def slow_api_call(user_id):
print(f"正在從遠端 API 取得 {user_id} 的資料... (這一步很慢)")
time.sleep(1) # 模擬網路延遲
return {"id": user_id, "name": f"User_{user_id}"}
print("第一次呼叫 123...")
start = time.time()
print(slow_api_call(123))
print(f"花費: {time.time() - start:.2f} 秒\n")
print("第二次呼叫 123...")
start = time.time()
print(slow_api_call(123)) # 這一瞬間就出來了
print(f"花費: {time.time() - start:.2f} 秒")CPU 不夠力 vs. I/O 卡住了:選對並行工具
當單一核心的效能被你榨乾後,就得考慮让電腦「一心多用」了。但這邊有兩個很重要的觀念要分清楚:`multiprocessing` (多進程) 和 `asyncio` (非同步)。很多人會搞混,但它們應對的場景完全不同。你去看看現在 104 上面那些資料工程師或後端工程師的職缺,很多都會要求具備處理高併發 (concurrency) 的能力,這時候你只會寫 for 迴圈是肯定不夠用的。
這部分其實有點複雜,但我們可以簡化成一個決策表。你可以根據你的「瓶頸」類型來選擇工具。
| 工具選擇 | 適合哪種情境? (瓶頸在哪) | 白話文解釋 | 什麼時候用? |
|---|---|---|---|
| Multiprocessing (多進程) | CPU 綁定 (CPU-Bound) | 你的程式一直在做大量的數學計算、圖像處理、壓縮... 就是 CPU 忙到停不下來。這就像你請了好幾個工人,一人負責一塊,大家一起動手做,事情當然快。 | 要對幾百萬張圖片縮圖、跑複雜的科學模擬、暴力破解密碼(喂!)。 |
| Asyncio (非同步 I/O) | I/O 綁定 (I/O-Bound) | 你的程式大部分時間都在「等」。等網路 API 回應、等資料庫回傳結果、等檔案讀取完。這就像一個廚師,他不用等第一鍋湯煮滾才去切第二道菜。他把湯放上爐子後,就立刻去忙別的,等湯好了再回來看。 | 寫爬蟲一次抓幾百個網頁、開發需要同時處理超多連線的聊天機器人或 Web API。 |
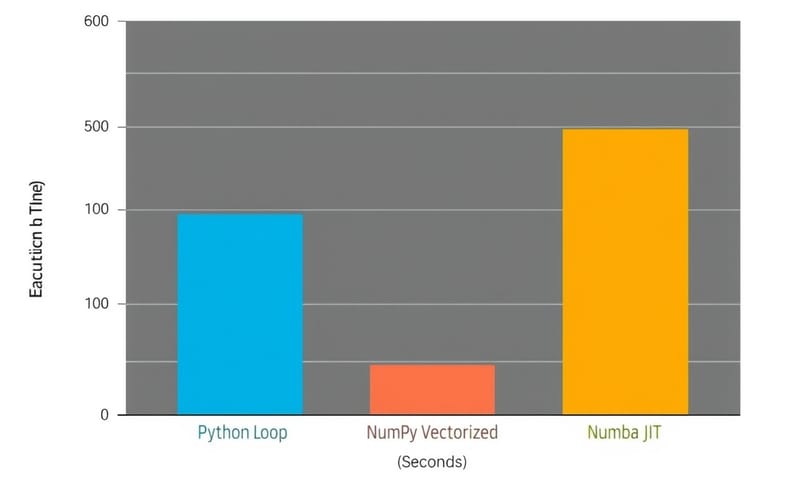
| Numba (JIT 編譯) | CPU 綁定 (純數值計算) | 如果你的瓶頸是纯 Python 迴圈裡的數學運算,它就像一個翻譯官,能把你的 Python 數字代码即時翻譯成超快的機器碼。 | 用 NumPy 還是嫌慢的科學計算、金融模型分析。但它對非數值操作就沒啥用了。 |
| Vectorization (向量化 with NumPy) | CPU 綁定 (陣列運算) | 你本來要用 for 迴圈對一百萬個數字做加法,现在直接跟 NumPy 說「把這整個陣列+1」,它底層會用超有效率的方式一次搞定。這叫批次處理,而不是一個一個來。 | 幾乎所有跟數據分析、機器學習有關的場景,你都應該優先考慮 NumPy。 |
所以你看,不是 `asyncio` 就一定比 `multiprocessing` 好,反之亦然。就像螺絲起子跟鐵鎚,你要先看你是要鎖螺絲還是釘釘子。用錯工具,效果只會更差。
最後的反思:別為了優化而優化
講了這麼多,我自己是覺得,最重要的還是要克制「過早優化」的衝動。什麼意思?就是你的程式根本還沒遇到效能瓶頸,你就開始套用上面各種複雜的技巧。
這會帶來幾個問題:
- 程式碼變超醜:為了那 0.01 秒的效能,把原本清楚明瞭的程式碼改成沒人看得懂的天書,值得嗎?三個月後回來看的你自己,絕對會想掐死當時的自己。
- 浪費生命:你花了一整天優化一個根本不常被呼叫的函式,結果專案裡真正慢的地方你動都沒動。這就是為什麼我一開始就說,一定要先 Profiling!
- 失去彈性:過度優化的程式碼通常都很僵化,不好修改,不好擴充。
老實說,大部分情況下,一個簡單、可讀性高的 `for` 迴圈,只要處理的資料量不大,就完全夠用了。程式碼的可讀性,在團隊合作裡,價值常常遠高於那一點點微不足道的效能提升。除非 Profiler 告訴你「喂!這裡就是火災現場!」,不然真的不要亂動。
所以,下次有人再吹噓 Python 跑得多慢,你可以笑笑地想,工具本身沒有好壞,端看你怎麼用它。你還有什麼私藏的 Python 效能調校祕技嗎?或是有踩過什麼有趣的坑?在下面留言分享一下吧!

