
我最近在跟一個 DevOps 工程師聊天,他說他工作上遇過最難搞的事,不是半夜服務掛掉要爬起來 debug,也不是解開那五百行天書一樣的 Terraform code。
你知道是什麼嗎?
是說服他的團隊,明明只用得到 0.2 顆 CPU,為什麼你們要申請 4 顆?這根本是在燒錢啊。
這真的說到心坎裡。老實說,大部分的 Kubernetes 클러스터 [cluster] 大概浪費了六到八成的資源。你的 Pod 申請了一堆 CPU 跟 memory,結果根本沒在用。團隊開了一堆儲存空間,結果 95% 都是空的。然後 AWS 帳單就默默地往六位數美金爬,但實際使用率可能連兩成都不到。
技術上的解法?很直接啊。Vertical Pod Autoscaler、resource quotas、好一點的監控… 隨便一個資深工程師,花一個週末大概就能搞定這些工具。
但真正的問題,從來都不是技術。
所以,問題到底在哪?
真實世界的情況是這樣:開發團隊說他們新的微服務需要 8 顆 CPU 跟 16GB RAM。你部署完,偷看一下監控數據,發現尖峰負載也就用了 1.2 顆 CPU 跟 3GB RAM。
這中間的成本差異,可能是每個月 $2,400 美金 vs 真正需要的 $400 美金。差了六倍。
但當你提議說「欸,我們來 right-sizing 一下吧,把資源調降到合理的範圍」,你聽到的會是:
- 「我們可能需要隨時快速擴展啊!」
- 「寧願多給也比不夠用好吧,保險一點。」
- 「反正我們的預算已經批下來了。」 (這句最經典)
你看,技術上的修正,五分鐘就搞定了。改一下 deployment 的 YAML 檔,重跑一次,收工。但組織上的修正… 那是要去改變人們對於基礎設施成本、效能需求、還有風險管理的「思維模式」。這才是真正難的地方。

那些真正會「規模化」的災難
技術債會累積,但「溝通債」和「觀念債」累積起來更可怕。你看過幾個經典場景:
成本優化?不存在的啦
有個團隊申請了 10TB 的頂級 SSD 儲存。八年後,我去看… 使用率 0.7%。每個月花 $3,200 美金養蚊子。還有另一個團隊,與其花時間去修一個 memory leak,他們選擇每季固定申請增加 RAM。結果六個月下來,光是「快速解決」的成本,就已經超過直接雇一個效能工程師了。
遷移專案的協調地獄
要把 2500 個微服務從 EC2 搬到 EKS,還要零停機時間。技術上這不複雜,service mesh 做流量切換都是很成熟的模式。但挑戰是,你要怎麼協調橫跨 12 個時區的 53 個開發團隊,裡面還有 36 個「核心服務」是上班時間絕對不能停的?這根本不是技術問題,是政治問題跟專案管理問題。
可觀測性的成本陷阱
喔這個超常見。團隊通常會把 Prometheus, Grafana, Jaeger, Elasticsearch, Fluentd 全家餐都裝上去。六個月後,他們的監控系統本身吃的資源,比他們真正在跑的應用程式還多。我看過一個例子,監控系統用了 12 顆 CPU、48GB RAM,結果是去監控一個只用 3 顆 CPU、6GB RAM 的應用。真的很荒謬。
DevOps 思維模式的轉變:傳統 vs. FinOps 導向
我自己是覺得,這一切都跟心態有關。你把自己當成一個「執行者」還是「管理者」?下面這個表,我自己整理的,可以看看你或你的團隊在哪一邊。
| 場景 | 傳統 DevOps 思維 | FinOps 導向的 DevOps 思維 |
|---|---|---|
| 新服務的資源請求 | 「先給我頂規,8 core 32G,不夠再加!以防萬一。」 | 「先給個最小的 0.5 core 1G 跑跑看,讓 VPA 給我建議,我們再慢慢調上去。」 |
| 效能問題處理 | 「又慢了?加機器啊!最快了。」 | 「慢在哪?是 memory leak 還是 query 沒寫好?先上 profiler 看看。」 |
| 監控與日誌 (Observability) | 「全裝!所有 metric 都收、所有 log 都存,以後總會用到。」 | 「這個 dashboard 是要回答什麼商業問題?這個 metric 變動時,我們需要採取行動嗎?不需要就先拿掉。」 |
| 看待雲端帳單 | 「那是會計部門的事吧…反正預算過了。」 | 「這筆費用是哪個團隊、哪個功能花的?有沒有優化空間?這直接影響到我們產品的毛利。」 |
看到差別了嗎?後者不只是在「做事」,他是在「經營」這個系統。
這個 FinOps 的概念,在國外像 FinOps Foundation 這樣的組織推動下,已經越來越普遍。但在台灣,老實說我觀察到另一種情況。有時候問題不是開發者貪心,而是公司的預算制度太僵化。年度預算一旦批下來,就沒有動力去節省了,因為今年沒用完,明年的額度可能就被砍了。這點跟 iThome 之前做的一些雲端成熟度調查有點像,很多公司還在「遷移上雲」的階段,根本還沒心力去想「成本優化」。
所以,到底該怎麼做?
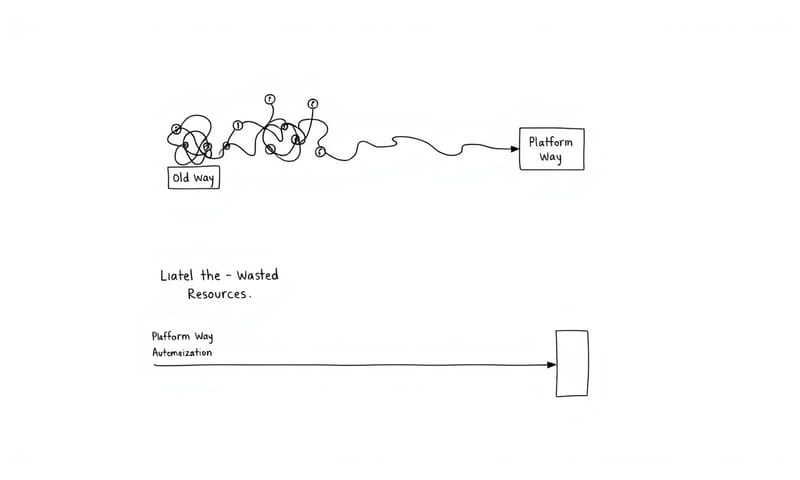
好,抱怨完了,還是要來點實際的。技術本身不難,難的是把它變成一個「預設選項」。這就是所謂的平台工程 [Platform Engineering] 的核心精神。
第一步:讓浪費「被看見」並設定基礎防護網
你不能只靠口頭勸說。你要讓數據說話,而且要讓浪費無所遁形。
1. 裝 VPA 來拿建議:
Vertical Pod Autoscaler (VPA) 會分析你的 Pod 實際用了多少資源,然後給你「建議值」。這就是最有力的證據。
# 1. 先把 VPA 的 CRD 裝起來
kubectl apply -f https://github.com/kubernetes/autoscaler/releases/latest/download/vpa-crd.yaml
# ...後面還有 controller 跟 recommender 要裝,可以去看官方文件2. 設定一個合理的預設值 (LimitRange):
防止有人手滑或根本沒概念,直接申請超大資源。給個很低的預設值,強迫開發者去思考他到底需要多少。
# 在 namespace 裡面放這個
apiVersion: v1
kind: LimitRange
metadata:
name: default-resource-limits
spec:
limits:
- default:
cpu: "100m" # 預設只給 0.1 顆 CPU
memory: "256Mi" # 預設只給 256MB RAM
type: Container3. 加上總量管制 (ResourceQuota):
避免單一一個 namespace 把整個 클러스터 [cluster] 的資源吃光。
# 一個 namespace 最多就只能申請這麼多
apiVersion: v1
kind: ResourceQuota
metadata:
name: team-a-quota
spec:
hard:
requests.cpu: "4"
requests.memory: 8Gi
limits.cpu: "8"
limits.memory: 16Gi
第二步:打造「精實可觀測性」 (Lean Observability)
不要再搞監控全家餐了。目標是讓監控系統的資源消耗,控制在整個集群的 15% 以下。
Prometheus 抓取頻率放寬:
你的服務真的需要每 15 秒抓一次數據嗎?大部分情況下,30 秒甚至 1 分鐘都很夠用了。這直接讓你的時間序列數據庫 (TSDB) 負擔減半。
# prometheus.yml
global:
scrape_interval: 30s # 不是 15s給監控工具本身也設限:
Prometheus 或 Elasticsearch 自己也是 Pod,當然也要設定 resource limits!不要讓他們無限增長。
# prometheus deployment yaml
...
resources:
requests:
cpu: 100m
memory: 512Mi
limits:
cpu: 1000m # 給個 1 核上限,不是無上限
memory: 2Gi # 給個 2G 上限,不是 8G第三步:建立安全的「多租戶」環境
當多個團隊共用一個 클러스터 [cluster] 時,隔離就變得很重要。你不能讓 A 團隊的網路流量打到 B 團隊,也不能讓 A 團隊的失控 Pod 影響到 B 團隊。
除了前面說的 ResourceQuota,網路策略 (Network Policies) 是必備的。預設應該是「全部拒絕」,然後再根據需要,一個一個開放。
# 一個預設全擋的 NetworkPolicy
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: default-deny-all
spec:
podSelector: {} # 選到這個 namespace 裡所有的 pod
policyTypes:
- Ingress
- Egress更進階一點,可以用像 Kyverno 或 OPA/Gatekeeper 這樣的 Policy Engine,去強制執行一些安全規範,例如「不允許使用 latest tag 的 image」、「必須要有 owner label」等等。這就是平台工程的威力:讓好的實踐變成自動化、無法繞過的規則。
這些行為模式,拜託別再做了
最後整理幾個我真的看到膩的「職涯殺手」反模式,如果你中了幾個,真的要小心:
- 警報疲勞 (Alert Fatigue):那個每小時跳 500 個通知、早就被所有人靜音的 Slack 頻道。這種警報有跟沒有一樣,只是在製造噪音。
- 文件戲劇 (Documentation Theater):寫了 40 頁的 Runbook,但兩個禮拜後就過期了,根本沒人會去更新,也沒人會去看。
- 複製貼上基礎設施 (Copy-Paste Infrastructure):給開發者一個自助平台,結果他們複製貼上一堆有問題的設定,你反而要花更多時間去幫他們擦屁股。
- 過早優化 (Premature Optimization):你的公司總共也就兩個客戶,你卻在設計一個可以服務百萬用戶的多租戶架構。拜託,先解決眼前問題好嗎。
- 監控瘋狂 (Monitoring Madness):追蹤一堆你永遠不會看的指標。問問自己:這個圖表掉下來的時候,我真的需要做什麼嗎?如果不用,它可能就沒有存在的必要。
重點一句話
說真的,那些在 DevOps 領域發展最快的人,不是精通 Kubernetes 或 Terraform 的技術大神。他們是那些懂得「商業脈絡」、能把技術決策跟商業價值連結起來的人。
他們是透過改變組織和流程,去解決一個五萬美金的成本問題,而不只是改幾行 YAML。他們打造的平台,讓好的實踐變成一種必然,而不是靠文件或口頭勸說來維持。
最難的問題,真的不在 YAML 檔裡。
好啦,換你說說。你遇過最扯、最浪費資源的要求是什麼?在下面留言分享一下吧,不用指名道姓,讓我們一起感受一下那種又好氣又好笑的痛。😂


