
你以為你在養第二大腦:結果只是把自己丟進一堆資料夾、標籤、回鏈的迷宮,然後在會議上腦袋空白。AI agents 用 RAG(檢索增強生成:先從你的資料庫找證據再回答)加向量嵌入(把文字轉成可比對的語意座標)做即時召回,讓筆記從「倉庫」變成「會動的工作記憶」。
- 你打字到一半,相關舊筆記自己浮上來,不用 CTRL+F 挖墳
- 不是靠你手動打標籤,而是靠語意去「猜你現在在幹嘛」
- 重點不是存更多,是把「想法→產出」那段卡住的時間壓短
- 要先搞清楚:資料來源範圍、權限、以及幻覺風險怎麼控
先講個刺痛的問題:你是不是也有那種「我明明寫過」的筆記,結果要用的時候像失憶。不是你記性差,是系統根本沒在配合人腦的跳躍。
我每次看到有人很認真維護 tag taxonomy,還做每週回顧把筆記「整理乾淨」,我都會…嗯,敬佩。然後想起我自己三天後就會放生。
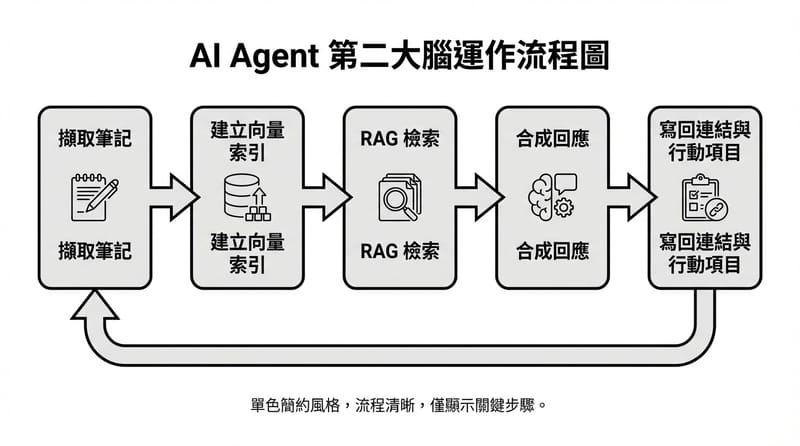
第二大腦為什麼常常爛掉
傳統 PKM 多半卡在「線性文件+靜態資料夾」這套,逼你用標籤與回鏈手工維護關聯;人腦卻是靠情境切換與快速聯想在運作,所以檢索成本會一路飆高,最後變成只存不取。
線性文件:你叫它筆記,我叫它時間膠囊。寫的時候很爽,半年後打開像看別人的草稿,然後你還得從第 1 行一路滑到第 80 行找那句關鍵話。很累。
標籤與資料夾:最常見的死法是「越分越細」。一開始是 Work/Personal,後來變成 Work/ClientA/2024/Q3/Meeting…你知道那個畫面。資料在,但你不想找。
圖譜工具也會翻車:Roam、Obsidian 那種雙向連結跟 graph view,本質上還是把「連結」的勞務外包給你。你得補連結、修命名、養結構。養到最後像在養盆栽,問題是盆栽不會幫你寫提案。
講到盆栽我突然想到一個更糟的:你用得越久,越不敢動舊筆記,怕一改就整串連結壞掉。然後你開始「新增一份」而不是「更新那份」。重複內容就像灰塵,堆很快。
進階指標別騙自己:不要只看「筆記數量」。看這三個就好:檢索時間(從想到到找到要幾秒)、回收率(寫過的東西實際被用回來的比例)、以及決策延遲(卡住的點是不是能被系統推你一把)。這三個才會痛。
AI agents 到底替你做了哪幾件苦工
AI agents 的差別在於「主動檢索+情境推斷」,不是等你下指令才動;它們會在你寫作、開會、規劃時即時拉出相關內容,並把新輸出回寫成可再利用的結構。
即時召回:你在 meeting 打到某個關鍵詞,六個月前那份討論紀錄就自己冒出來,還順便把當時的決議、負責人、後續沒做的事情列出來。那種感覺很怪,像你腦內突然有人幫你翻書。
語意搜尋取代關鍵字狩獵:關鍵字搜尋常常失敗在你「現在用的詞」跟「當時寫的詞」不一樣。語意搜尋是抓概念相似度,不是抓字面相同。你找的是意思,不是拼字。
自動長出連結:不是你坐在那邊想「這篇要連到哪」。而是系統看到你正在寫 A,順手把 B、C、D(你以前寫過、跟 A 有共同語意)推到旁邊。你只要決定要不要用。
回饋迴路:傳統筆記最慘的是沒有 feedback loop,寫完就封存。Agent 的玩法是:你用過一次,它就記得「你在這個情境下會採用哪種資訊」,下次更準。你可以把它當作一個會被你訓練的偏好模型。你越懶,它越該扛。
不過先別嗨。真的別。
你要是把一個「會亂講」的模型接到你的工作流,它就不是第二大腦,它是第二個亂源。這個等一下講風險。

底層不是魔法 是 RAG 加一堆很瑣碎的工程
RAG(檢索增強生成)會先把你的筆記、文件、逐字稿切成 chunk 並做向量嵌入,查詢時用相似度從向量資料庫撈出證據,再交給 LLM(大型語言模型:用機率生成文字的模型)整合成回覆,重點是把回答綁回「你自己的資料」。
你問問題:例如「上次我們談那個定價策略,最後怎麼定的?」
它先判斷意圖:是要「結論」、要「當時的理由」、還是要「相關檔案」。意圖抓錯就全盤歪掉。
它去撈資料:向量資料庫(例如 FAISS、Milvus、Pinecone 這類)用 embedding 相似度把候選片段抓出來。這步其實很看你切 chunk 的方式,切太碎像碎紙機,切太大像搬整本書。
它再生成回覆:LLM 把那些片段「壓縮成你現在用得上的句子」。這裡你要逼它引用來源片段,至少能回查,不然你會被它的自信口吻騙到。
最後要回寫:把新結論、行動項、連結,寫回你的系統。很多人做到前面很興奮,卡在回寫,因為牽涉到格式、權限、版本控管。瑣碎,但決定你會不會長期用。
題外話,講到版本控管我就想到:你如果筆記散在 Notion、Google Drive、Slack、Zoom、手機語音備忘錄,那個權限跟同步就像拼圖,少一片就整張爛。這也是為什麼「跨 app」其實是最值錢、也最容易翻車的一段。
外部可查的東西:如果你要做「會議逐字稿→摘要→行動項」,常見基礎是 OpenAI Whisper 這種 ASR(自動語音辨識)模型;權限跟個資處理就得回到你公司規範,台灣這邊至少要想《個人資料保護法》跟內部資訊安全要求,不然哪天 audit 你會很難交代。
來源定錨:幻覺這件事,NIST 的 GenAI 風險框架(AI RMF)跟 OWASP Top 10 for LLM Applications 這兩套都有把「輸出不可信」跟「資料外洩」列成重點(來源:NIST AI RMF[2023];來源:OWASP Top 10 for LLM Apps[2024])。我知道聽起來很官腔,但踩過一次你就懂。
幾個用起來真的會爽的情境 以及我覺得最危險的坑
AI agents 最能打的情境是「會議即時召回、研究綜整、跨工具串接、語音轉工作流」,但同一套也最容易踩到「權限過大、引用不清、回寫污染」三個坑,所以要設計可回溯與最小權限。
會議即時召回:你在講到一個舊決策,agent 直接把當時的討論摘要丟出來,還附上原文片段。這種時候你會看起來像準備很久,其實你只是有人幫你翻資料。很賊。
研究綜整:丟一疊白皮書或規格文件,讓它先做「一頁紙」的重點,然後你再追問「這個結論的依據是哪段」。注意順序:先壓縮,再回查,再寫結論。不要反過來。
文章或提案共想:不是 brainstorming 那種亂噴點子,而是它把你以前寫過的句子、你收過的引用、你做過的反對意見整理出來,逼你面對「你其實早就想過」。很有效,也很不舒服。
跨 app 串接:Notion 寫著寫著,順手把 Drive 的文件段落拉進來,再把 Slack 上你上週丟的那句吐槽當作風險提示。這個真的爽,但也最容易外洩。因為你一旦讓它「什麼都看得到」,它就什麼都可能吐出來。
語音到工作流:開車講一段碎念,回家變成 task list,還幫你掛上專案脈絡跟截止日。這種才叫「減少摩擦」,不然你只是把摩擦從鍵盤搬到手機。
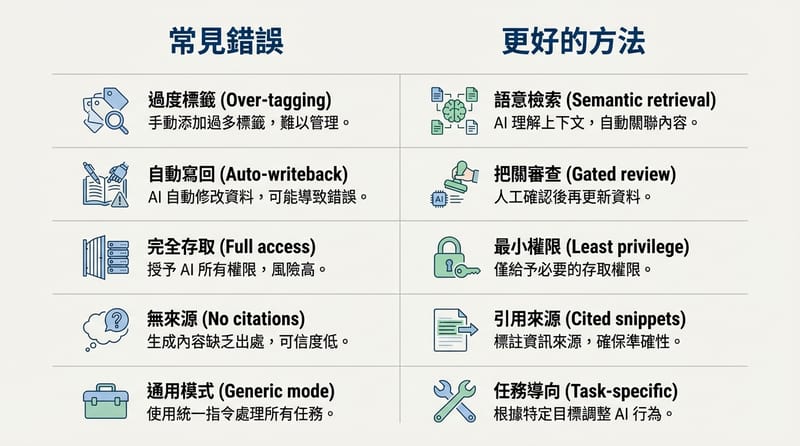
最危險的坑 1:回寫污染:agent 生成的內容如果直接寫回你的知識庫,久了你會得到一個「被模型語氣洗過」的資料庫。全部都像同一個人寫的。然後你再用它訓練或檢索,會越來越偏。很像自我催眠。
最危險的坑 2:引用不清:它講得很肯定,但你不知道它是根據哪份筆記、哪段逐字稿、哪個版本。這種系統我不敢讓它參與決策,只敢讓它當「提示器」。
最危險的坑 3:權限過大:你把 Slack、Drive、Notion、Email 全接了,結果某次它把不該出現在那個場合的內容帶出來。你會冷汗。真的。
「第二大腦不是存得多,而是你卡住時,它能不能把那段你早就寫過的關鍵證據丟回你面前。」
台灣通路避雷指南 你買工具前先看這段
在台灣挑 AI agent 或第二大腦工具,先把資料放哪裡、是否支援離線、以及能否做到本機或私有化部署列為第一優先,因為個資法、公司資安稽核、與跨境傳輸疑慮會直接決定你能不能長期用。
先講價格區間感:多數 SaaS 型的筆記+AI 助理,月費常落在每人新台幣 300–1,000 左右;如果你要企業方案、SSO、稽核紀錄、資料保留策略,那個數字會再往上跳一段(來源:公開資訊,建議查證)。我知道你想問「有沒有免費的」,有,但通常是你自己用時間付費。
通路怎麼挑:
- 網購平台:App Store / Google Play 上的「語音轉文字+摘要」類工具很多,先看權限要求,尤其是聯絡人、相簿、全檔案存取。要是它一開口就要全拿,先不要。
- 企業採購:如果你在公司導入,先問 IT 要求什麼:SSO、SCIM、資料加密、日誌、DLP。你跳過這步,後面會被打回票,浪費一個月。
- 實體通路:老實說,AI agent 不是去燦坤或全國電子買盒子回家插就好,真正要買的是「服務+政策」。你在實體店看到的多半是周邊硬體(錄音筆、耳機、NAS),重點是你打算把資料放哪裡。
避雷 1:只看功能頁不看資料流:你要看的是「資料從哪裡進來、存在哪裡、誰能讀、怎麼刪、怎麼匯出」。尤其是匯出。你不想被綁死。
避雷 2:看到『不會幻覺』就笑一下:沒有這種事。比較務實的問法是:它有沒有強制引用、能不能限定只用你的資料、能不能把不確定的地方標出來。
避雷 3:在台灣潮濕環境講離線其實很現實:你在捷運、地下室、偏遠工廠,訊號就是會斷。離線可用(至少能記錄、能暫存)不是浪漫,是避免你靈感直接蒸發。
工具指引:如果你想先用「官方資料庫」或標準來做基本盤,資安跟治理我會先拿 NIST AI RMF 跟 OWASP Top 10 for LLM Apps 當 checklist;如果是個人端,至少做到「資料可匯出、引用可回查、回寫有審核」。不然你最後會得到一個漂亮的混亂。
反對意見我先替你講 然後我們來吵一吵
AI agents 不是萬靈丹,因為資料治理、權限控管、引用回溯、與回寫審核沒做好就會把混亂放大;但把 agent 只當聊天機器也很可惜,因為 RAG 與語意檢索能把「想起來」的成本壓到幾秒內。
你可能會說:「我筆記整理得很好啊,我不需要。」
可以。你如果真的做得到「三秒找到、五分鐘重用」,那你已經贏一堆人了。只是我會想追問:你維持那個狀態,每週要花多少心力?你是不是靠意志力在撐?
你也可能會說:「agent 會亂講,我不敢用。」
合理。我的解法不是相信它,而是把它關進籠子:只用你自己的資料、回答要附引用片段、回寫要經過你確認、權限採最小化。把它當一個會犯錯的助理,不是神諭。
我比較想聽你的:你覺得第二大腦最該被替換的,是「整理」那段,還是「回想」那段?還是你其實最痛的是「寫完後根本沒再用到」?你選一個,我們直接對打,別客氣。

