
有個數字先丟出來:在 Kaggle 這種比賽裡,很多人可以把訓練集 accuracy 拉到 99% 以上,但一上線、資料一變,表現掉到「看起來像壞掉」的情況超常見。這不是你笨,是你只練了「筆記本模型」,沒練到「現場模型」。
關鍵快照:你想把深度學習模型訓練到能上線,重點不在 model.fit(),而是把「資料管線(清理/前處理/增強/批次)→ 優化器與學習率 → 正則化與評估(含 early stopping)→ 偏誤/可解釋性/耗能」這整條流程做得穩,才不會研究室很神、現場直接翻車。
- 先查資料:缺值、離群、格式不一,先抓出來,不然後面全在賭運氣。
- 管線要快:GPU 等資料是最貴的浪費,真的。
- 學習率是炸彈:太大爆炸、太小龜速,調不對就像迷路。
- 不要迷信 accuracy:你要的是泛化,不是背答案。
- 還有倫理:偏誤、黑盒子、耗電,這些不是「之後再說」。
為什麼筆記本裡很準,上線就崩?先從「資料」當嫌犯
模型從 notebook 到 production 會翻車,最常見原因是資料分佈變了(data shift),或資料管線在訓練與上線不一致。資料不是「餵進去就好」,資料是你整個案子的第一現場。
偵探直覺:你看到訓練曲線漂亮到像假的,先別高潮。先問:「我訓練時看到的資料,跟上線時真的一樣嗎?」
講到「一樣」,我就想到一個超常見的小坑:訓練時你把缺值補成 0,上線時缺值變成空字串或 NaN,然後整個特徵工程崩一半,模型就開始亂講。你會以為是模型爛,其實是資料在搞鬼。
還有那種:訓練資料是白天拍的照片,上線資料晚上拍的;訓練資料是某個地區的文字用語,上線資料突然混進另一個圈子的黑話。你不處理,模型就像只會解一套題目的考生。
模型的命運,常常在第一個梯度算出來之前就決定了:資料管線如果歪,後面再強的網路也救不回來。
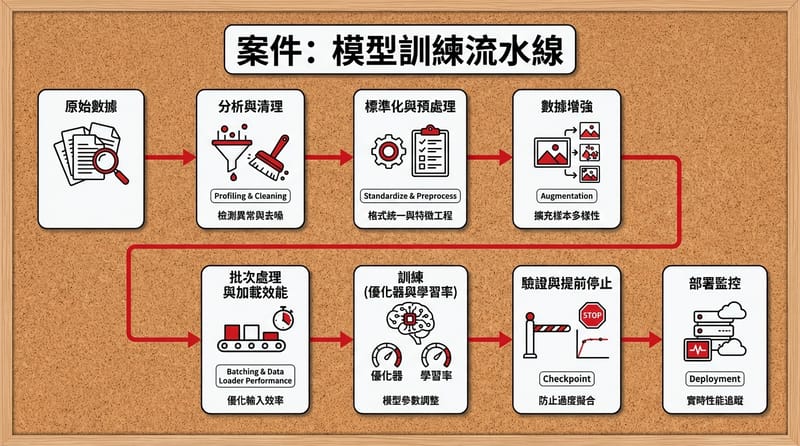
資料管線怎麼做才不會餓死 GPU:清理、前處理、增強、批次
穩健的 machine learning pipeline 需要四件事:資料剖析與清理、標準化數值表示、合理的 data augmentation、以及高效率的資料載入與 batching。這四個少一個,訓練就容易慢、偏、或看起來很準但其實很脆。
1) Analyze & Clean(先驗屍):先做資料剖析(profiling)。缺值比例?離群值在哪?欄位型態是不是亂七八糟?
你可以用很土的方法:先印幾筆、看分佈、看最小最大。也可以用工具一點的:像 pandas 的 describe、或資料驗證工具(Great Expectations 這類)把規則寫下來,之後每次資料一更新就自動抓異常。這步做了,你會少掉很多「怎麼突然壞了」的夜晚。
2) Standardize Representation(統一口供):把輸入都變成一致的數字格式。影像常見是把 pixel 值縮放到 0~1;文字要 tokenize;時間序列可能要 resample。目標很單純:讓模型吃到的東西穩定、尺度一致,優化器才不會像在碎石路上滑倒。
3) Implement Augmentation(做幾個假目擊者):資料增強其實就是「同一件事,換個角度再講一次」。影像翻轉、旋轉;文字同義詞替換;感測器資料加一點合理噪聲。
但這邊我會碎念一下:增強要「符合領域」。你如果把醫療影像左右翻轉,可能直接把左右器官顛倒…嗯,這就不是增強,是製造冤案。
4) Optimize for Efficiency(不要讓 GPU 等你):GPU 很貴。它坐在那邊等 CPU 慢慢讀檔、慢慢前處理,像請了刑警結果讓他去排隊買便當。
常見做法是:用多執行緒/多程序把資料載入和前處理並行跑,讓 GPU 訓練的同時,下一批資料在 CPU 那邊先準備好。框架像 PyTorch 的 DataLoader(num_workers、prefetch 之類的設定)就是在解這個問題。
批次大小(batch size)呢?這個超像選車道:大 batch 通常效率好、吞吐高;小 batch 有時泛化比較好,但訓練會比較抖、也可能比較慢。你要看硬體、看資料、看你到底在趕什麼。
突然想到一個很實際的:台灣夏天濕到爆,機房散熱或辦公室空調不夠,GPU 降頻你還以為是 pipeline 慢。對,這也算「現場因素」。有點扯,但真的遇過。
優化器、學習率:真正的引擎在這裡,調錯就翻車
神經網路訓練本質是高維度最佳化問題:你要找到一組權重與偏置,讓 loss function 最小。選擇 SGD、Adam 等 optimizer,以及學習率(learning rate)與 scheduler,會直接影響收斂速度與最終表現。
SGD(Stochastic Gradient Descent):最基本、也最像老派辦案:一步一步往「讓 loss 下降最多」的方向走。它能用,但有時會慢,還會卡在地形很爛的地方。
Adam:比較像有經驗的刑警:會記得你前幾步往哪走(momentum),也會針對不同參數調整步伐大小(adaptive learning rate)。所以很多深度學習任務,Adam 一上來就能當一個不錯的 baseline。
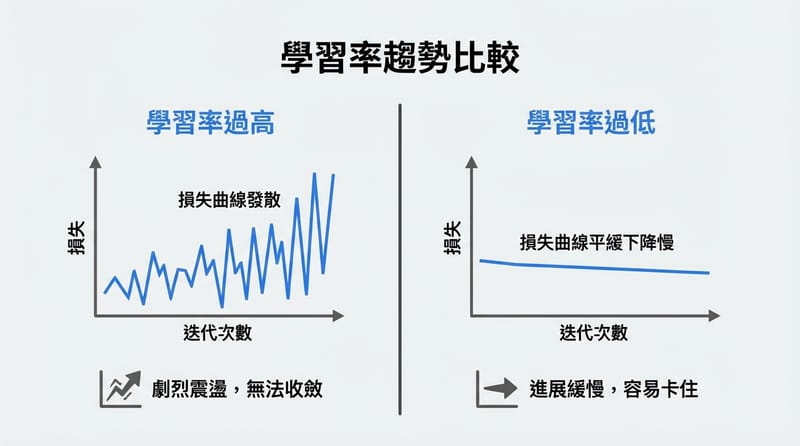
學習率是最大嫌犯:學習率太大,loss 會亂跳甚至直接發散;學習率太小,你會訓練到天荒地老,還可能卡在不太好的解。
我上課時老師有一句話我一直記著:「你可以先選 Adam,但你不能不管 learning rate。」這句很兇,但對。
你真的要用 scheduler(例如訓練到後面慢慢降學習率),那感覺像:一開始大步快跑抓線索,快接近真相時就放慢,不然你會衝過頭。
Quick win(但不吹神話):多數專案先用 Adam 當起點,學習率先用常見預設值附近開始試,再視 loss 曲線和 validation 表現調整。不要一開始就搞得像在拼奧賽。
別再只看 accuracy:泛化、正則化、early stopping 才是你要的證據
模型真正的成績是 generalization:在沒看過的新資料上表現如何。為了避免 overfitting,常用方法包含 L1/L2 正則化、dropout,以及 early stopping 監控 validation 指標並在最佳點停止訓練。
Overfitting 長什麼樣?訓練集一直變好,驗證集開始變差。你如果還硬訓下去,就像一直逼證人背稿,背到最後只會背那份稿,遇到新問題就啞口無言。
L1/L2:在 loss 裡加一個「權重不要長太大」的成本。概念很直白:不要讓模型用極端的參數去硬記。
Dropout:訓練時隨機把一些神經元關掉。這招有點像:你不准同一個證人一直講同一句話,逼整個團隊都要懂案子,最後模型學到的表示會比較穩。
Early stopping:這個我真的偏愛。因為它很像偵探的「收手」:你看到 validation 不再進步,就停在那個最像真相的位置,不要貪。
實作上,你通常會:
- 切一份 validation set(不要偷懶用 training 當 validation)
- 每個 epoch 看 validation loss/metric
- 連續 N 次沒進步就停(patience)
很樸素。但有效。
倫理與現實:偏誤、黑盒子、耗能,這三個你躲不掉
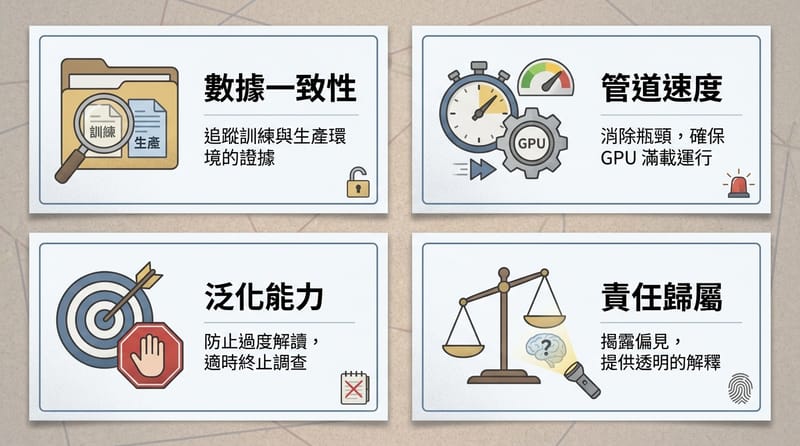
現代模型評估不只看技術指標,還要檢查公平性(bias/fairness)、可解釋性(XAI)、以及訓練的環境成本(energy/carbon)。這些因素會影響模型在醫療、金融等高風險場景的可用性與責任歸屬。
公平性與偏誤:資料偏,模型就偏。這句很煩但是真的。你至少要做一件事:分族群/分條件看指標,不要只看一個總平均。
我之前做功課查到,很多團隊會用「不同群體的錯誤率差距」當警報線;你不用一開始就把 fairness 研究論文全讀完,但你要先承認:平均值會藏屍體。
可解釋性:在醫療、金融這種場景,你不能只說「模型說的」。你要能回答:為什麼它這樣判?這時候像 SHAP、LIME 這種方法就會被拿出來用(至少讓人能看懂模型大概在看什麼特徵)。
環境成本:大模型訓練耗電很兇,這不是道德綁架,是成本問題。電費、機房、碳排,最後都會回到你身上。
題外話一下:你如果在台灣用雲端訓練,帳單跳出來的那一刻,心臟會漏拍一拍。嗯。這就是「可持續性」最直白的教育。
台灣通路避雷指南:工具、雲端、硬體,怎麼買才不踩坑
在台灣把模型從 notebook 推到 production,常踩的坑是「硬體規格看不懂、雲端費用沒估、資料驗證沒工具」。用 Great Expectations 做資料規則、用 MLflow 做實驗追蹤、並先用小規模 GPU(例如 RTX 4060/4070 等級)驗證流程,通常比一開始就租大機器更省錢也更穩。
先講結論:不要一上來就買最貴、租最大。先把流程跑順,才知道你到底缺哪裡。
你可能會去哪買?我把「通路」當成三個案發地點來看:
- 電商(PChome / momo / 蝦皮):方便,但規格文常常寫得很像猜謎。你要盯的是顯存(VRAM)和散熱,不要只看「幾GB 記憶體」那種模糊字眼。
- 原價屋、欣亞這種組裝通路:你可以直接問店員「我要跑深度學習,顯存要多少比較不痛?」通常比你自己瞎配好。缺點是你得有一點點基本概念,不然容易被帶著走。
- 雲端 GPU:彈性很爽,但費用最容易失控。尤其你忘記關機、或把資料搬來搬去,帳單就會開始演恐怖片。
價格區間(很粗但可用):以「先把流程跑起來」來說,入門到中階的單卡主機,很多人會落在新台幣 3 萬~8 萬之間(看你 CPU/記憶體/顯卡型號)。雲端則是「按小時燒錢」,你不做預算上限就等著哭。
避雷 1:只看 CUDA 核心數,不看 VRAM。你最後會卡在 batch size 小到像在用吸管喝珍奶。
避雷 2:資料管線沒做快,上了雲端也沒用。GPU 還是在等你。
避雷 3:實驗沒紀錄。你調過哪些 learning rate、哪次用了 dropout、哪次換了資料版本,你忘了就等於白做。
工具上,我會建議你至少摸兩個:
- Great Expectations:把「資料應該長怎樣」寫成規則,資料一歪就抓到。
- MLflow:把參數、指標、模型版本記起來,不然你永遠只記得「那次好像比較準」。
對了,如果你做的是會牽涉個資的資料(例如使用者行為、醫療、金融),台灣這邊至少要有個概念:個資法的基本要求、資料去識別、存取權限控管。這不是法律建議啦,但你別裝沒看到。
你不是在訓練一個模型,你是在訓練一整套「不會被現場打臉」的流程。
小挑戰:給你 30 分鐘,挑一個你手上的專案(或隨便找一個資料集也行),只做三件事:
- 把資料 profiling 做出來(缺值/離群/型態)
- 加上 early stopping(真的加,別只說說)
- 把一次訓練的參數和指標記下來(用 MLflow 或你自己的紀錄方式)
做完你再回頭看,你會突然知道:以前你以為在「訓練模型」,其實你在「猜」。
如果你願意,再加碼一題:你能不能說出你模型最可能偏誤的族群是誰、為什麼?這題很硬,但就是要問。為什麼。🤔

