
你有沒有遇過這種狀況:同事丟一句「我們用 AWS 的 AI 就好啊」,你腦子第一個反應不是「好耶」,而是——到底是哪一個 AWS 的 AI? 🤨
因為 AWS 不是只有一個「AI 服務」。它是一整櫃抽屜,抽屜裡還有抽屜。你一打開,Bedrock、SageMaker、Kendra、Lex、Textract…每個名字都像嫌疑犯。看起來都很像。也都說自己無辜。
先給一句可以直接拿去吵架的答案:如果你要在 AWS 上做 AI/ML,通常會落在三條主線:生成式 AI 用 Amazon Bedrock / Amazon Q、自建模型與 MLOps 用 Amazon SageMaker AI、現成 AI API(文字、影像、語音、文件)用 Comprehend、Rekognition、Transcribe、Textract;剩下那些像 A2I、DevOps Guru、Fraud Detector 是「特定場景的加速器」。
- 想用大模型做功能:先看 Amazon Bedrock(再看要不要加 Guardrails、RAG、微調)
- 想讓工程師少打字:Amazon Q Developer;想讓員工查資料:Amazon Q Business
- 想把資料做成模型:SageMaker AI(Autopilot/Canvas/Pipelines/Feature Store 這幾個最常被點名)
- 想直接解決單一任務:Textract 抽文件、Transcribe 聽寫、Translate 翻譯、Polly 轉語音、Rekognition 看圖
- 怕模型亂講又要稽核:A2I 做人審工作流,留 audit trail
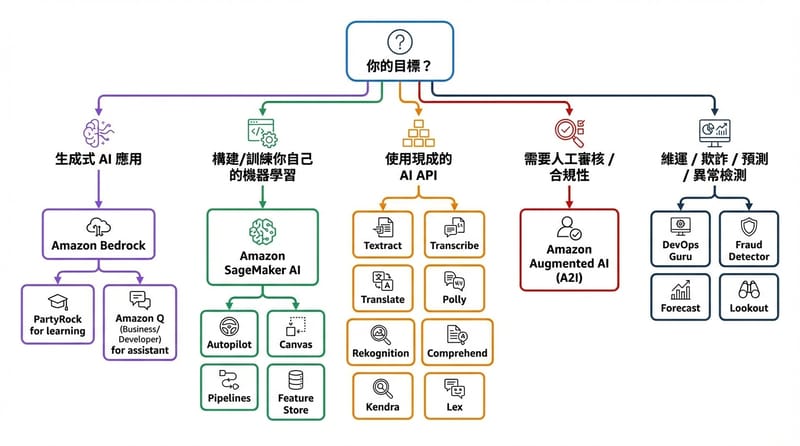
先把嫌疑犯分組,不然你會越看越像
Amazon Bedrock、Amazon SageMaker AI、Amazon Q 是 AWS AI 版圖的三個核心實體:Bedrock 偏向「用與客製化基礎模型」、SageMaker 偏向「建模訓練部署與 MLOps」、Q 偏向「把生成式 AI 變成助理,接到你的企業資料或開發流程」。這樣分,才不會每個服務都像在搶戲。
偵探筆記:很多人卡住的點其實很單純:你到底要「模型」還是要「功能」。你如果只是想要功能(抽文字、翻譯、聽寫),別急著跳進 SageMaker 那個宇宙。
但 AWS 的命名真的…嗯。像是你去便利商店買水,結果冰箱裡每瓶都叫「純淨」,只是副標不同。😅
講到「副標」,我突然想到:很多團隊會把「AI」當 KPI,然後就開始挑看起來最帥的那個。Bedrock 這名字就很帥。石頭。基座。很穩。
可你要的是穩,還是要快?先別急,往下查。
Amazon Bedrock:想用大模型,先問三件事
Amazon Bedrock 是 AWS 的受管 API,用來存取與客製化 foundation models,包含 Amazon 自家模型與多家供應商的模型,提供無伺服器體驗,支援用私有資料微調與部署,並由 Bedrock 代管擴縮、版本與模型託管。費用以 API 呼叫計價,沒有預付承諾。
三個問題:
- 你要的是「聊天」還是「把模型嵌進產品流程」?前者 demo 很快,後者才是血淚
- 你能不能接受資料治理的要求?(公司內規、客戶合約、資安稽核)
- 你要不要微調?還是其實 RAG 就夠了?
原文有列合作夥伴那串:AI21 Labs、Anthropic、Cohere、Meta、Mistral AI、Stability AI,還有 AWS 自家的 Nova models。這串名字你可以當「可選嫌疑犯清單」。
我自己的偏執提醒:不要一開始就把「微調」當救命。很多時候是資料沒整理好、檢索沒做好、提示詞沒收斂,然後你就把錢丟進微調…最後得到一個更自信地胡說八道的模型。很尷尬。
對了,Bedrock 旁邊那個 Amazon PartyRock 是很「教學玩具」的定位:不用寫程式做小 app、練 prompt。你要推內訓、或讓非工程背景的人先玩出感覺,它蠻好用。
但如果你要上線賺錢…嗯。先別用玩具當主力。真的。
Amazon Q:同事問你問題,你可以叫它去回
Amazon Q 是生成式 AI 助理家族,其中 Amazon Q Business 偏向「接企業系統資料來回答、摘要、生成內容並完成任務」,Amazon Q Developer 偏向「協助開發、測試、升級、除錯、資安掃描與優化 AWS 資源」,前身是 Amazon CodeWhisperer。這兩個方向差很多,不要買錯方向。
偵探式拆解:你聽到「Q」先不要激動,先問:用的人是「全公司」還是「工程師」。
因為全公司那種,常常最後會變成:大家拿它問 HR 規章、問 SOP、問「我們這個客戶到底誰在跟」。
工程師那種,就變成:PR 裡面它幫你抓問題、或你把一坨 log 丟給它要它說人話。
你看,兩種世界。
SageMaker AI:你想掌控全流程,代價就是你要真的管
Amazon SageMaker AI 是用來建置、訓練與部署機器學習模型的全受管平台,涵蓋資料準備、標註、訓練、調參、部署、監控與 MLOps,目標是讓模型更快進入生產並降低基礎設施管理負擔。SageMaker AI 的子服務包含 Autopilot、Canvas、Clarify、Data Wrangler、Feature Store、Pipelines、JumpStart、HyperPod 等。
我知道你會懷疑:「受管不是應該很省事嗎?」是。也不是。它省的是機器跟環境,但你還是得面對資料品質、標註一致性、特徵漂移、部署後監控…那些你躲不掉的東西。
好,快速把幾個常見角色講完(不然你會迷路):
- Autopilot:你丟表格資料、指定 target,它幫你自動建模、訓練、調參,做分類/回歸。適合先做 baseline
- Canvas:給商業分析或非工程的人用的視覺化建模介面。點一點就能跑預測
- Clarify:抓 bias、做可解釋性(feature importance 那種),產報告。稽核跟法遵會愛它
- Data Labeling:標註資料那條路,含人力流程管理(你也可以接 A2I 的概念)
- Data Wrangler:資料整理、清洗、特徵工程。原文說「從幾週縮到幾分鐘」——這句我會打個折,但方向沒錯
- Feature Store:特徵集中管理與版本追蹤,訓練/線上推論一致性那個痛點它在處理
- Pipelines:ML 的 CI/CD。把資料到部署串起來,讓你每次重訓不是靠手動祈禱
- JumpStart:一鍵部署解決方案或開源模型、也能 fine-tune。適合「先跑起來再說」
- HyperPod:偏大型模型訓練的基礎設施管理,講白了就是「你要訓練很久很大,別讓它半路死」
- Edge:把模型丟到邊緣裝置跑,還能 OTA 更新,並且監控
- Geospatial:地理空間資料那套(衛星、地圖、空間分析),跟一般 tabular 不同宇宙
看到這裡你可能想翻桌:怎麼那麼多。
對。就是多。
一個比較「務實」的切法:你若是新手團隊,通常先碰到的是 Autopilot / JumpStart(快速出東西)、Data Wrangler(資料整理)、Pipelines(把流程固定)、Feature Store(避免每個人各自算特徵算到翻臉)。
現成 AI API:Comprehend、Textract、Transcribe、Translate、Polly、Rekognition
AWS 的現成 AI API 服務(例如 Amazon Comprehend、Amazon Textract、Amazon Transcribe、Amazon Translate、Amazon Polly、Amazon Rekognition)主打「不用 ML 專業也能透過 API 做 NLP、文件抽取、語音轉文字、翻譯、文字轉語音、影像與影片分析」。這類服務通常適合快速上線、成本可預估、也比較容易切分責任範圍。
逐一拆:
- Comprehend:文字的語言偵測、情緒、關鍵片語、實體(人名地名品牌)、主題分類;還有 AutoML 做自訂實體/分類
- Comprehend Medical:醫療文字抽「疾病、藥物、劑量、關係」那種,並用到 ICD-10-CM、RxNorm、SNOMED CT 等本體
- Textract:文件 OCR 升級版,能抓表單欄位、表格結構,甚至用 query 抽特定資訊;也能接 A2I 做人工複核
- Transcribe:語音轉文字,支援即時與批次,還有 word-level timestamps
- Transcribe Medical:醫療語音聽寫,偏醫療生命科學場景
- Transcribe Call Analytics:客服/銷售電話那套,轉錄 + NLP 洞察,做 Contact Center Intelligence 常見
- Translate:神經機器翻譯,支援即時與批次,按字元計費那種
- Polly:TTS,含 Neural TTS、Newscaster 風格,還有 Brand Voice(客製聲音)
- Rekognition:看圖看影片:物件、場景、活動、不當內容、臉部分析與搜尋;Custom Labels 可用自家資料訓練
小心點:這段有碰到醫療(Comprehend Medical、Transcribe Medical)就會進到合規議題,例如 HIPAA-eligible。這不是「按一下就合法」。你還是要看你的資料處理流程、權限、稽核、保存政策。
我上課時老師常講一句(很煩但有用):合規不是產品功能,是你整個系統的行為。嗯。
企業搜尋與對話:Kendra 跟 Lex 不是同一種聊天
Amazon Kendra 是企業搜尋服務,用 ML 做自然語言查詢並從文件、FAQ、內網與資料庫抽出精準答案,提供連接器與搜尋分析;Amazon Lex 是用 Alexa 同款技術做聊天機器人與語音助理,負責 intents、對話流程、slot filling 與錯誤處理。Kendra 解的是「找得到答案」,Lex 解的是「把對話走完」。
常見誤會:有人以為「我有 Lex 就有企業問答」。不一定。
Lex 很會「跟你聊」,但它不一定知道你公司內網那份 PDF 寫了什麼;Kendra 很會「找」,但它不負責把你用戶的情緒安撫好。
你如果要做客服 bot,常見做法是:Lex 管對話,後面再接搜尋或知識庫(Kendra 或你自己的檢索)。
這裡我先停一下。
不然我會一直想把「聊天」跟「檢索」這兩個概念混在一起,然後你也會被我帶歪。
把不確定交給人:Amazon Augmented AI A2I
Amazon Augmented AI(A2I)用來建立「人審」工作流,讓 ML 預測在信心不足或高風險情境時自動送交人工複核,並提供任務模板、審核紀錄、audit trail 與 confidence scores,支援 AWS 內建或外部人員。A2I 的價值在於把人工審核變成可管理的流程,而不是臨時找人看一眼。
我覺得它很像什麼:像你辦案時的「第二雙眼睛」。你不是不相信模型,你是不相信模型永遠不會走神。
尤其是 Textract 抽發票、或 Rekognition 做瑕疵檢測,抽到一個怪怪的結果,你要不要直接寫入系統?還是要先讓人看一下?
這時候 A2I 就是那個「把人放回流程裡」的工具。
模型不是拿來取代人的,模型是拿來把人的注意力用在「最該看」的那 5% 上。
異常、詐欺、預測、設備:這些是特定場景的捷徑
Amazon DevOps Guru、Amazon Forecast、Amazon Fraud Detector、Amazon Lookout for Equipment、Amazon Lookout for Vision、Amazon Monitron 等服務,屬於「針對特定業務或工業場景」的受管 ML 解法:DevOps Guru 做營運異常與根因建議,Forecast 做時間序列預測,Fraud Detector 做即時詐欺風險評分,Lookout/Monitron 做設備與影像的異常偵測與預知維護。
逐個點名一下:
- DevOps Guru:看 latency、error rate、資源使用率,抓異常,給 root-cause 分析與修復建議,能用 CloudFormation stack 或 tag 分群
- Forecast:時間序列預測,會把促銷、價格、天氣等變數一起考慮;原文提「可比只用歷史序列的傳統方法準 50%」這種敘述你當參考值,因為準度很看資料
- Fraud Detector:吃交易、裝置、行為資料,做即時 scoring;有常見詐欺情境模板
- Lookout for Equipment:吃震動/溫度/壓力感測器資料,做設備異常預警
- Lookout for Vision:用標註圖片訓練「正常 vs 異常」視覺模式,抓缺陷
- Monitron:更像整套包到好:感測器 + gateway + 服務 + app,幾分鐘可裝,偏工廠維護
超關鍵提醒:Amazon Lookout for Metrics 原文有寫一個時間點:AWS 會在 2025 年 10 月 10 日停止支援。這不是小事,因為你如果現在還要新導入,風險很高。
我會直接把它當「冷門嫌疑犯,準備退場」。
你看,辦案就是這樣,有人會消失。😐
開發框架與環境:MXNet、PyTorch、TensorFlow、Hugging Face、DLAMI、DLC
Apache MXNet、PyTorch on AWS、TensorFlow on AWS、Hugging Face on AWS,以及 AWS Deep Learning AMIs 與 AWS Deep Learning Containers,這一群是「你要自己掌控框架與環境」時會用到的選項:AMIs 提供預配好的 EC2 深度學習環境,Containers 提供預裝框架的 Docker 映像,並可在 SageMaker、EKS、ECS 或自管 Kubernetes 上跑。
說人話:你如果覺得「我不要被平台綁死」,那你就會更常碰到 Containers;你如果想快速開一台機器就能訓練,AMIs 會比較舒服。
Hugging Face on AWS 這條路則是:你想用 Transformers 生態系,直接接 SageMaker 跑 fine-tune 或部署 endpoint。
對了,這種地方很容易踩一個坑:環境版本。
你昨天能跑,今天不能跑。就這樣。
台灣通路內行人避雷:買服務不是買名字,是買帳單的可控性
在台灣真的常見一種場景:公司採購會先問「你們要買哪個 AWS 服務」,然後下一句是「有沒有上雲補助」或「能不能走既有合約」。你如果回答不清楚,專案就會被丟回來重寫,像被退件。很煩。
避雷指南:
- 先確認你走哪種通路:台灣常見是 AWS Marketplace、台灣本地代理商/經銷夥伴(含雲端 SI)、或你公司既有的 AWS Enterprise 合約。不同通路對「報價呈現方式」差很多
- 生成式 AI 先抓「每次呼叫」的成本輪廓:Bedrock 是按 API 呼叫計價,你要先做一個「日活 × 平均 tokens/次 × 峰值」的粗算,不然後面每個人都會怪你
- 試用/POC 要卡住上限:用 AWS Budgets(工具名給你了)設預算告警,還有 Cost Explorer 去回溯,別讓 POC 變成月末爆單
- 醫療/個資場景不要只看服務寫 HIPAA-eligible:台灣實務還要看你公司的個資與資安政策、委外合約、資料保存與存取控管。這種東西不是 PM 一句「應該可以」就能過
- 停更服務別碰:Lookout for Metrics 已公告 2025/10/10 停止支援,別在新案子裡當核心依賴
價格區間怎麼抓?我不報「精準數字」給你,因為 AWS 定價牽涉區域、用量、折扣、承諾用量,而且每家公司拿到的合約條件差很大。
但你可以用兩句話在會議上保命:
「先用 Budgets 卡上限,POC 先跑出單位成本,再談要不要擴。」
這句真的救過很多人。包括我這種低能量的人。
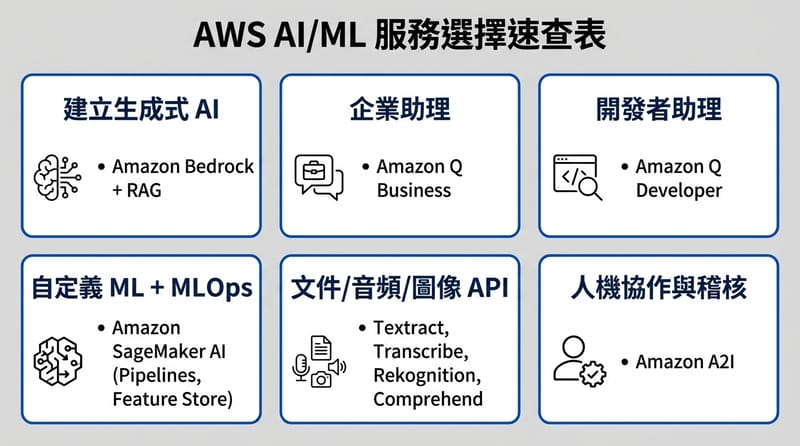
結尾前的那張圖:你把需求寫清楚,服務自然就會掉出來
把 AWS AI/ML 服務選對的關鍵不是背名詞,而是把需求拆成「資料型態、即時性、風險、可解釋性、維運責任」五個維度,然後對照 Bedrock、SageMaker、現成 API、A2I、人機流程與合規要求去選。你越想偷懶用一句話概括,越容易買錯服務,最後用時間補洞。
小挑戰:用 10 分鐘做一次你的選型偵查
挑戰規則:你現在就挑一個你手上「想做 AI」的需求(哪怕很小),用下面三句話寫出來,寫完就算破案一半:
- 資料是什麼:文字/圖片/音訊/表格/文件 PDF?來源在哪?
- 要多快:即時(秒級)還是批次(小時/天)?
- 出錯會怎樣:只是體驗差,還是會造成金流/法遵/醫療風險?
你寫完之後,再回頭對照上面的分組:Bedrock?SageMaker?現成 API?要不要 A2I?
如果你願意,再加一題加分題:你能不能用 AWS Budgets 先把成本上限卡住。
就這樣。先別急著把所有服務背起來。

